5 reasons your ML model isn’t performing well in production
Liran Hason
6 min readApr 05, 2021
Liran is the CEO of Aporia
We’ve all been there. You’ve spent months working on your ML model: testing various feature combinations, different model architectures, and fine-tuning the hyperparameters until finally, your model is ready! Maybe a few more optimizations to further improve the performance score, but it’s ready for the real world.
You either hand it over to the engineering team or prepare it yourself for production.
It’s showtime! Your model will be making real predictions – ones that people care about and that have an impact. This is an extremely exciting moment after so much hard work.
Now that the model is in use, performance is crucial. Unlike traditional software, where you rely on exceptions to be thrown, ML models fail silently. Your model won’t tell you whether it has been receiving data with a shifted distribution, missing features, or even that the concept entirely has changed. We usually only find out that something went wrong when it’s too late when the real world forces us to update our priors, and we learn that our model’s performance has degraded.
Why your ML model may be underperforming
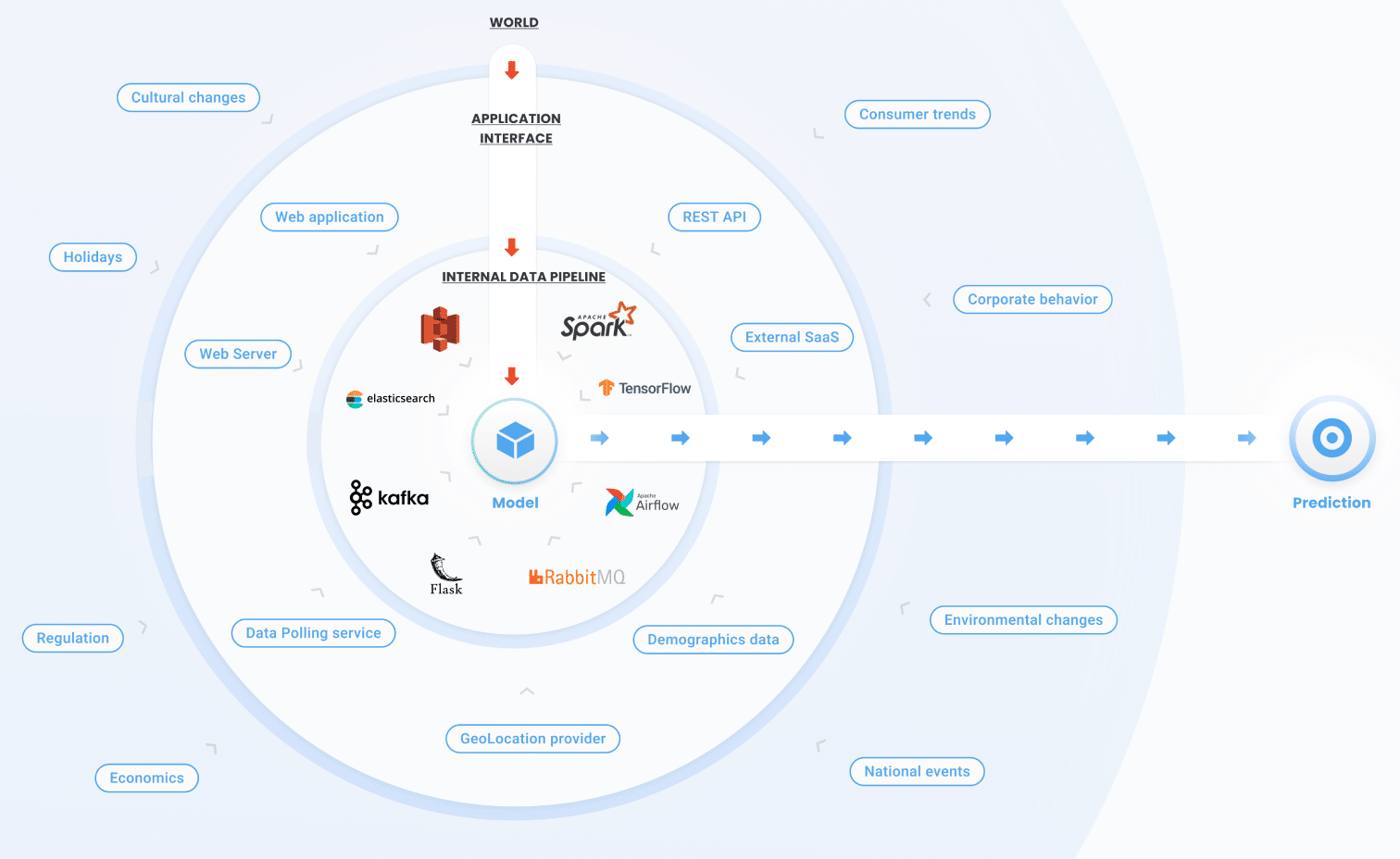
World
1. Change in reality (Concept Drift)
The training dataset represents reality for the model: it’s one of the reasons that gathering as much data as possible is critical for a well-performing, robust model. Yet, the model is only trained on a snapshot of reality; The world is continuously changing. That means that the concepts the model has learned are changing as time passes by and accordingly, its performance degrades. That’s why it’s essential to be on the lookout for when concept drifts occur in your model and to detect them as soon as possible.
There are various types of concept drifts that are further discussed in our Concept Drift in Machine Learning 101 post.
Application interface
2. Engineering vs. data science “lost in translation”
In many organizations, there’s a separation between the team which builds the models (data scientists) and the team which is in charge of them in production (engineering/ML engineers). This separation often occurs because of differences in programming language expertise or simply due to different organizational structures.
In these situations it is quite common to see production models, implemented by the engineers, being quite different from the data scientists’ intended implementation. Consequently, the production model’s logic is unintentionally different than the expected logic.
3. Application Updates
Often, the ML model will be utilized by applications that are developed entirely by other teams. A common problem that occurs is when these applications are updated/modified and consequently, the data that is sent to the model is no longer what the model expects. All this without the data science team ever knowing about it.
Internal Data Pipeline
4. Feature processing bugs
Data goes through many steps of transformation before finally reaching the ML model. Changes to the data processing pipeline, whether a processing job or change of queue/database configuration, could ruin the data and corrupt the model that they are being sent to.
5. Data schema changes
Once trained, the model expects as an input a particular data schema. Changes to the schema, due to feature transformation or even earlier stages of the data pipeline, could result in malformed features being sent to the model.
● ● ●
Using indicators to detect common issues with your model
These common issues can be detected by looking for the right indicators. Here are just some of the ways in which they can come about:
» Dropped fields
When processing jobs fail they often leave important fields empty. Other times, a third-party vendor may simply omit or deprecate a field in their API without notice. When this happens, the model is not receiving data for fields that it is trained on and expecting. While some models are able to deal well with missing values, many are not.
» Type mismatch
Due to changes in a third-party data source or due to internal data pipeline changes, the model might encounter unexpected types of data. It might receive a “Big int” when it was expecting an int; or a unicode string when it was expecting ASCII. We’ve all also encountered situations when fields that should be ints are interchangeably both ints and strings (as well as vice versa!). All these situations often cause unnecessary processing errors and incorrect predictions.
» Default value change
We all use default values in our code: it could be 0, it could be -1; maybe your default value of choice is NaN or something even better. Code, and especially the model, assume that the default value will not change. Another team changing their default value without notifying the data science team is a common source of problems, resulting in unexpected inputs and unexpected behavior of the model.
» Values out of range
When working with data, we usually start by analyzing it. We look for unique values, examine the value ranges, and the general distribution. Input values that are out of the scope of the model’s expectations could result in unexpected predictions.
» Distribution Shifts
Another subtle problem that can arise is when there is a distribution shift in one or more of its features. While data might appear ok in regards to data integrity, the model’s behavior might change due to such a shift in distribution that occurs over time.
» Performance metrics degradation
We often have to make do with subpar labels before production. Once high-quality labels are available, it becomes possible to re-evaluate the model’s performance. This is the most conclusive metric for detecting model degradation. Unfortunately, in most use-cases it can take weeks, months, or even years until high-quality labels are available. Waiting for high-quality labels for re-evaluation might result in late detection of issues after serious damage has already been done.
● ● ●
Time to diagnose why your model isn’t performing well
Let’s take a real-estate company’s ML model as an example. They trained a model to predict housing prices across the country. Yet in practice, the model may only be performing well on a few specific neighborhoods, but poorly on many others. If the real-estate company is informing their strategic decisions on the model’s predictions, disparities in performance across neighborhoods could be disastrous.
Changes in the real world, broken data pipelines, and everything in-between alter the shape and content of the data that is ultimately fed to your model. Changes in the feature vector will be reflected in the model’s performance, perhaps resulting in predictions that are quite different than what the model was trained to do.
The tricky part is that problems often take a lot of time to surface. Your model doesn’t live in an echo chamber, surrounded by its training data, but in a complex ever-changing world, full of moving parts that impact its performance.
Without proper visibility and monitoring, your model is at risk of underperforming without your knowledge and without any ability to discover the cause. A proper monitoring platform will allow you to gain full visibility and early detection of production issues. With such a system in place, you can guarantee that your models are performing well and as you trained them.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.



 Alon Gubkin
Alon Gubkin




