Over the last year and a half, there has been a major leap forward in the text-to-image space, where deep learning models are capable of transforming any form of text into an uncurated image. We’ve been amazed by the advancements that OpenAI and its DALL-E models have made, along with the rivaling launch of Google’s Imagen model – a text-to-image diffusion model that uses large transformer language models to comprehend the text and produce high-quality, super-realistic images. While you’ve probably already seen one of the hundreds of hysterical memes floating around social media, when playing around with the model, I found myself deep in the realm of ML bias.
Throughout history, it has been the artist’s trade to interpret imagination and description into visual masterpieces. However, the introduction of these new perceptible models has definitively put the art in artificial intelligence. Just imagine a small penguin conducting an orchestra of vegetables. Funny as it may sound, it’s these types of Natural Language Processing models that pose the next generation of human-AI interaction. Imagine it, type it in, and it will appear.
Bias in Text-to-Image Models
Although, game-changing at its core, text-to-image models have significant limitations, especially when considering the ethical aspect of AI. The text-to-image models’ data requirements often rely on massive web scrapes that are largely uncurated, thus creating datasets based on real-world information. The issue here, as we all know, is that the internet is not always fair or PC, and often it will represent offensive, discriminatory social stereotypes that marginalize certain people and cultures. This was the case when I recently played around with DALL-E Mini, an NLP model created by Boris Dayma, that’s an attempt to reproduce OpenAI’s DALL-E but with an open-source model.
Now, to give credit to the model’s creators, they quickly added a Bias and Limitations disclaimer, noting that the model was trained on unfiltered data from the internet. It’s also worth noting that since I first played with the model, things have changed, learning has taken place and the biased text-to-image outcome has improved.
How the DALL-E Mini Model Works
The way the model works is pretty simple – type in some text and watch it produce an image. What’s really cool about the model is that it doesn’t search and populate images from the internet but actually creates never before seen visuals based on the text that is typed in. So what happened when I tested it out? Take a look…
Finding Unintentional Bias with DALL-E Mini
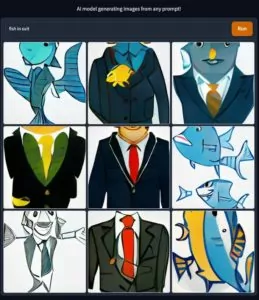
I first typed in a completely random text to test it out – “fish in a suit” was the first thing that came to mind, and as you can see it presented several examples of a fish in a business suit.
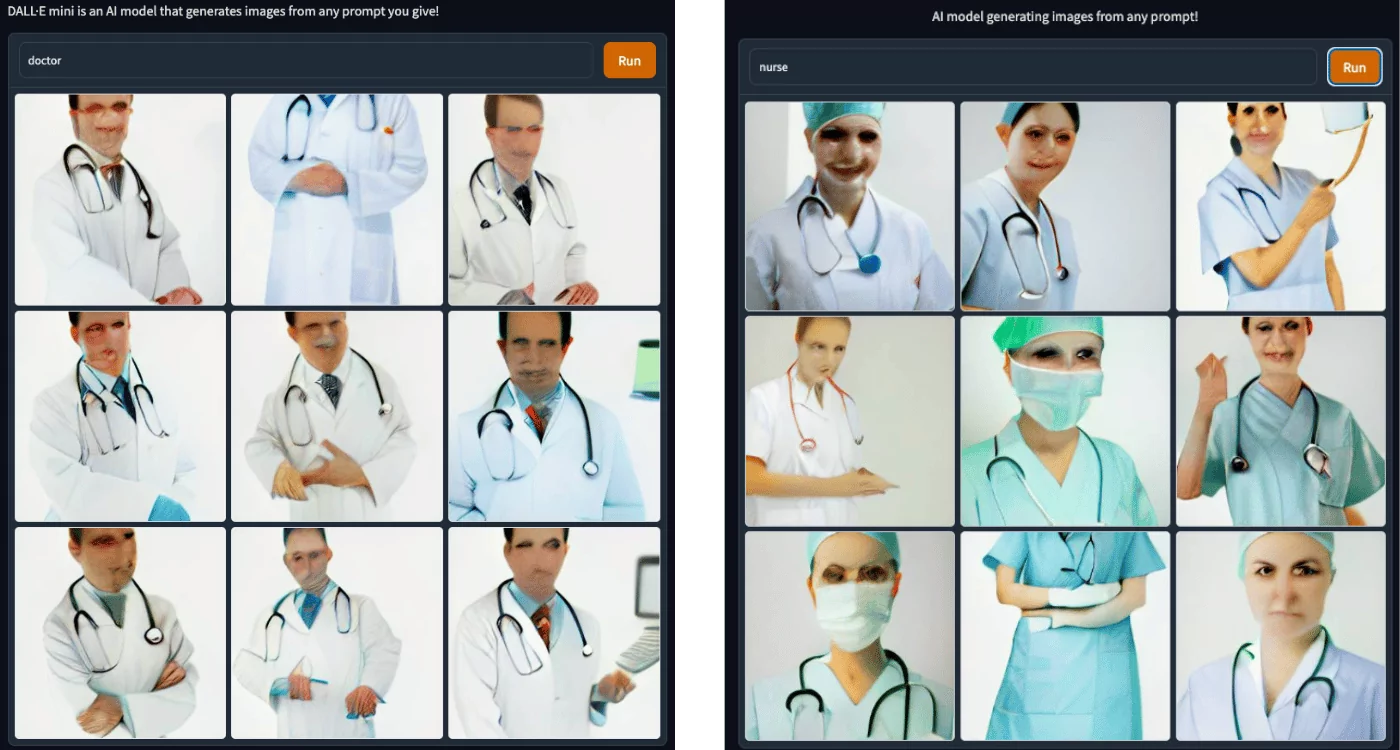
Next, I tried typing different professions to see which images come up. I typed in “doctor”, which was immediately populated by white men in white coats. This example highlights the unintentional bias exhibited within the model – the word “doctor” is not inclusive of all genders and races.
But when typing in “nurse”, we see the gender role flip, with the images showing what looks to be all white women.
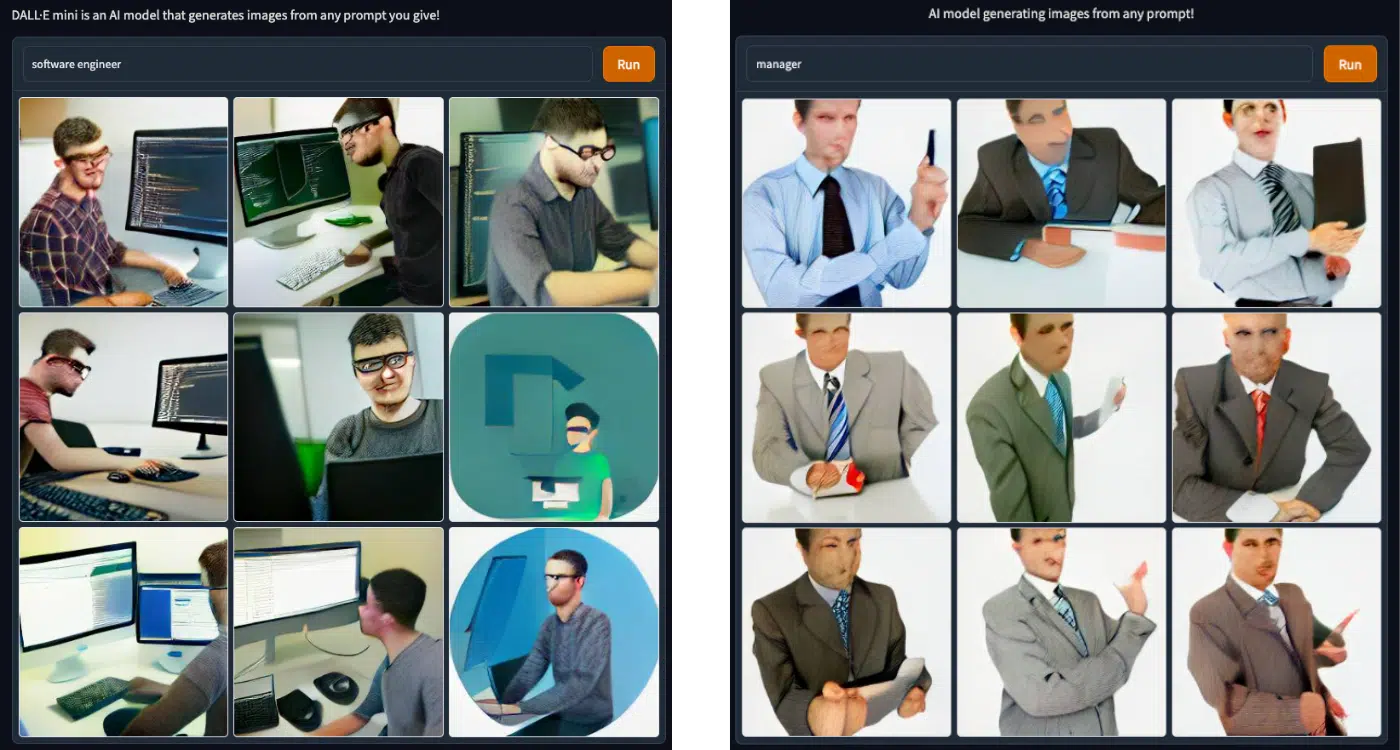
At first glance this could be based on biased learnings of decades of images of white male doctors or female nurses scraped from the web. In contrast, a quick Google search of “Doctor” results in a diversified library of images. But what happens when a more modern profession – like “software engineer” – is typed in? And better yet, what biases will we see if I type in “manager”?
Again, we see that a high-valued profession is populated solely with images of white men in front of a computer wearing glasses. Now, as more and more women have entered the world of software engineering, I expect images like these to be more inclusive with regard to gender and race.
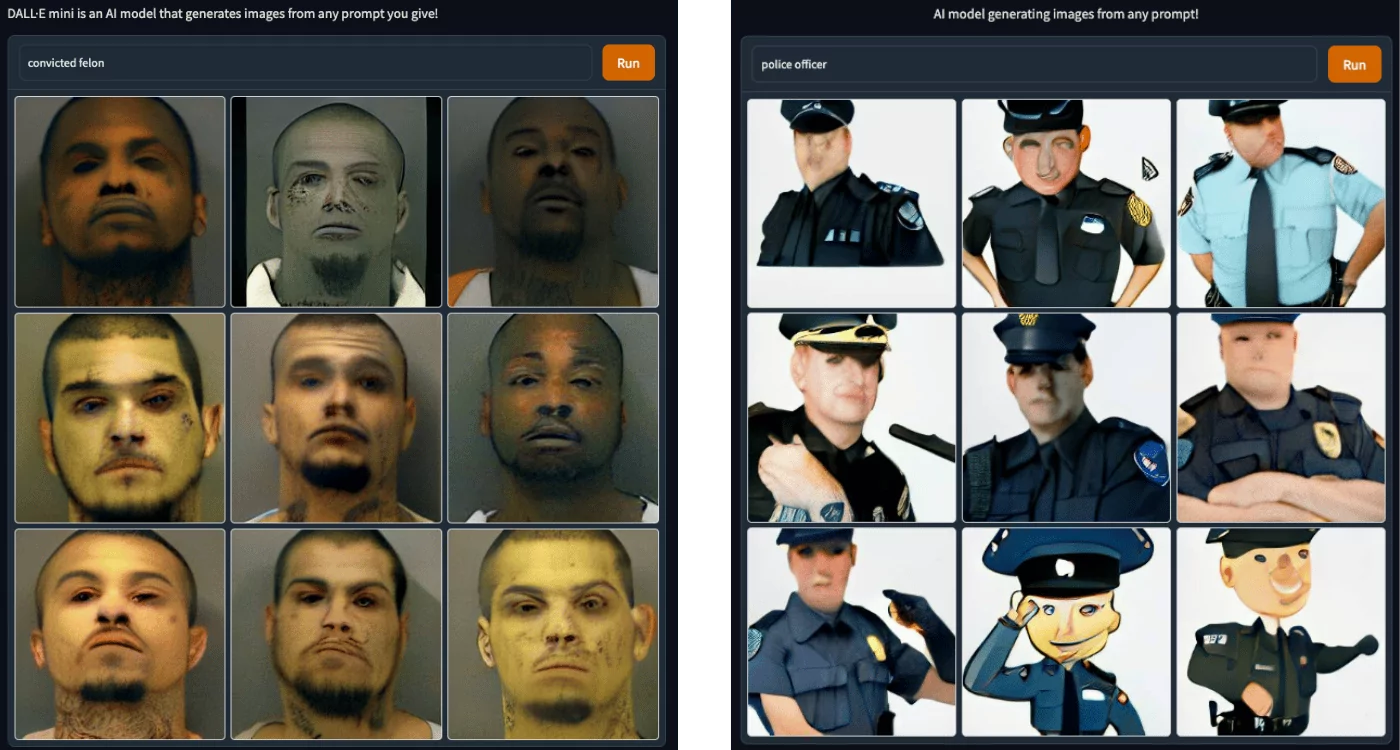
However, when I type in “convicted felon” suddenly we see a distinct change in the race of the populated images. We see other ethnicities other than caucasian show-up, and we see the appearance of tattoos as some kind of visual representation of something negative.
Thinking about the other side of the coin, I typed “police officer” to see what came up. Sure enough, I was reminded again of the bias in these models, as you can see for yourselves – all the images are of white men in uniform.
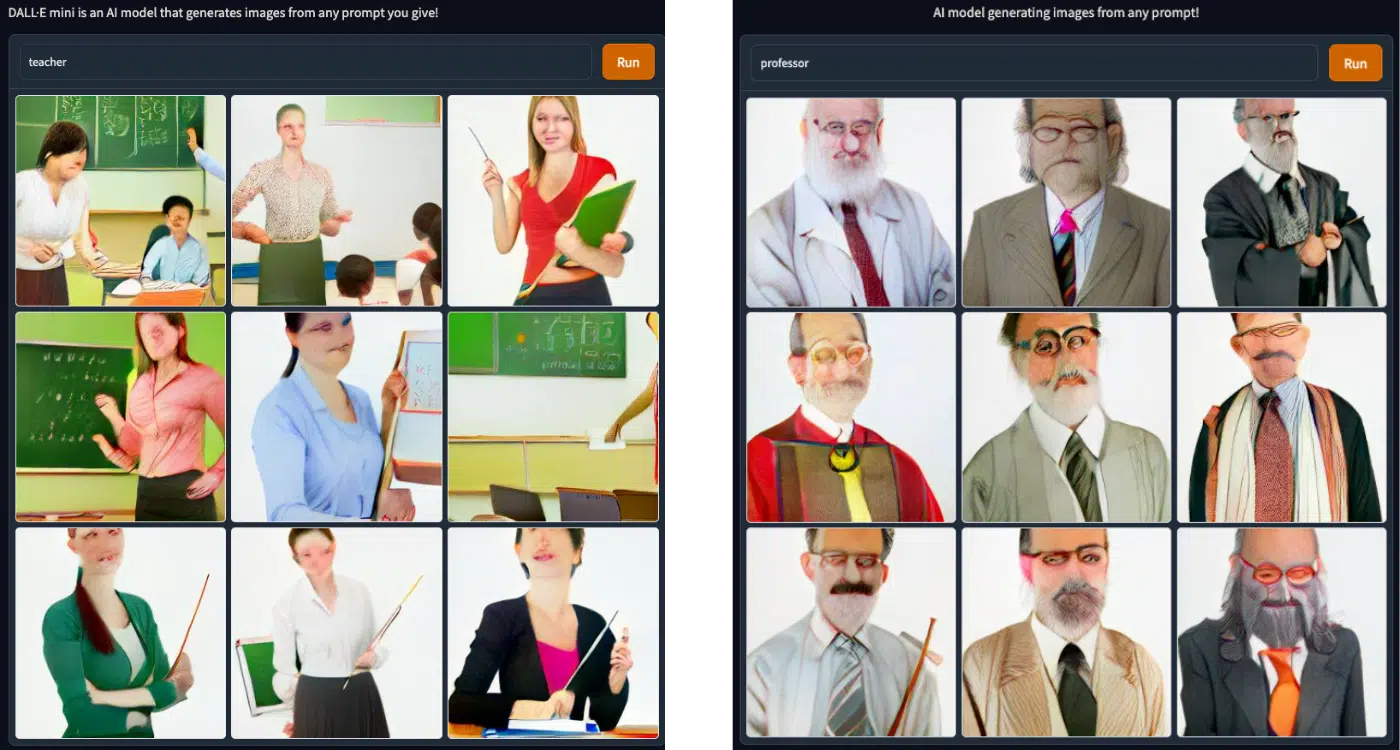
Continuing on, I tried to challenge the model by typing in the word “teacher” to see if the role is labeled as female. Right next to the “teacher” I typed “professor”. I wanted to check if the higher education profession was reserved for strictly men, despite the research showing a near 50-50 split down the middle in the US.
Throughout modern history, and according to the data, there is a major gender gap when it comes to teachers, with women making up the lion’s share of educational professions. With the “professors” we see a kind of Hollywood stereotype of the educated white man with glasses and a beard.
Another interesting thing to notice in all of the images above – is that all the people in the images have a similar body type, which again goes against everything our eyes see in the real world and could be considered a form of unintentional bias.
Why Fairness is Critical to Trust AI
As these text-to-image models are meant to represent real-world values, we can clearly distinguish 3 major discriminations for race, gender, and body type. Remember, these machine learning models represent the next step for society-impacting innovation, therefore these biased images dramatically affect the fairness component of practicing Responsible AI, which in turn can stall the evolution of the practical application for these models.
What Can We Learn from the DALL-E Mini Model?
Regardless of intention, and the effort to ensure we don’t have bias in our models, unintentional bias creeps in through real-world data. How can we leverage ML models while ensuring they remain fair and unbiased?
Proactive monitoring of machine learning models is a great place to start. Platforms like Aporia can offer a comprehensive overview of machine learning models in production, providing visibility, monitoring, explainability, and investigation tools to ensure ML models are performing as intended.
I expect that as AI continues to evolve, there will be a call for stronger guardrails and regulatory action, to help ensure the integrity and reliability of these NLP models. Cooperation between ML model creators from academia, data science teams, and business stakeholders is needed to guarantee that bias and fairness issues are fixed before they negatively impact people.
Try it yourself, and let us know what unintentional bias you find ????
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.




 Aporia Team
Aporia Team


