As your data science team grows and you start deploying models to production, the need for proper ML infrastructure becomes crucial – a standard way to design, train and deploy models. In this guide, together we will build a basic ML Platform using open-source tools like Cookiecutter, DVC, MLFlow, FastAPI, Pulumi and more. We’ll also see how to monitor for model drift using Aporia. Final code is available on GitHub. Keep in mind that this type of project can be huge – often taking a lot of time and resources – therefore our toy ML Platform won’t have tons of features – just the basics, but it should teach you the basic principles of how to build your own ML platform. This how-to guide is based on the following workshop I did for the MLOps Community:
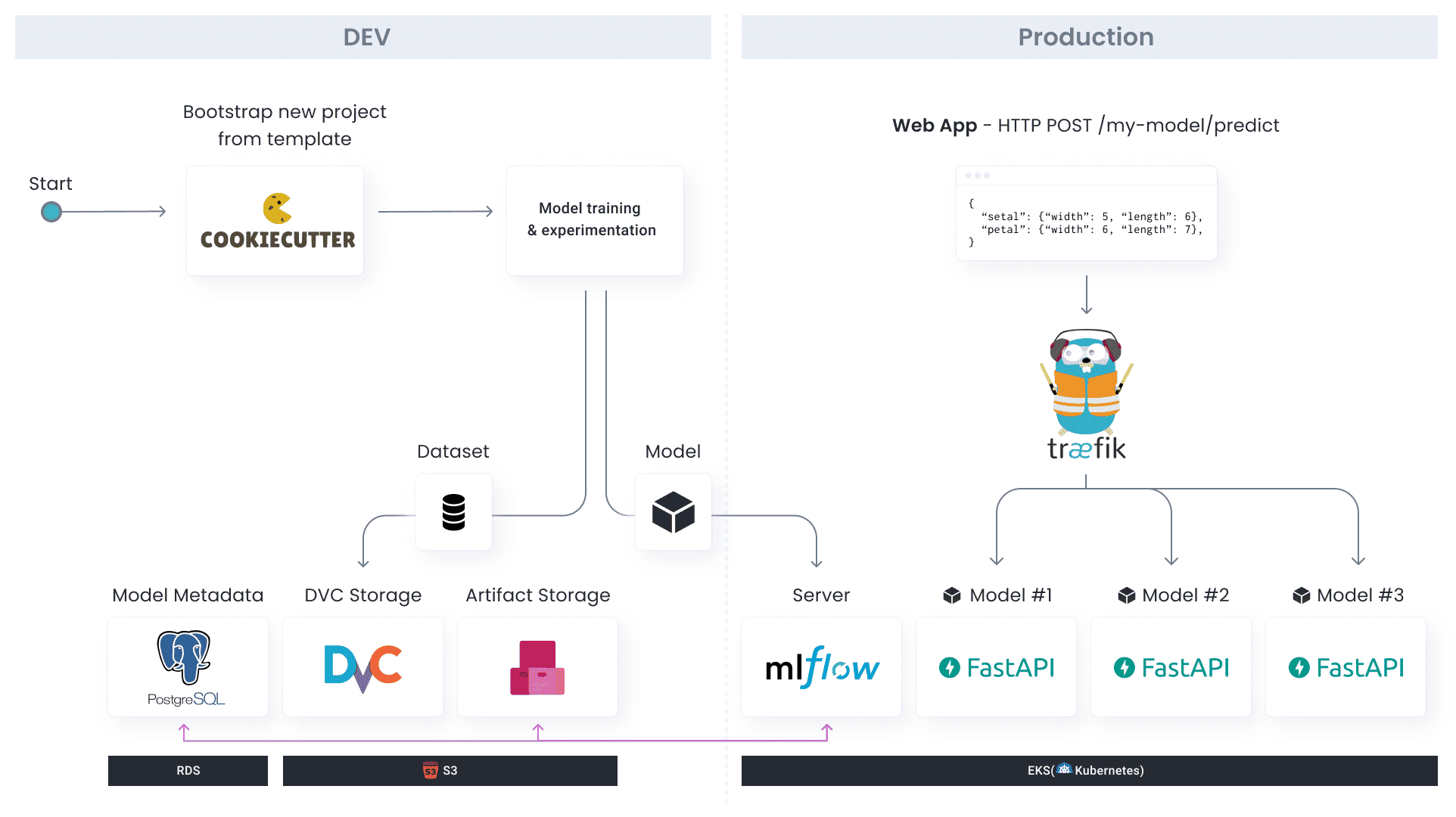
Architecture
Our toy ML Platform will use DVCfor data versioning, MLFlowfor experiments management, FastAPIfor model serving, and Aporiafor model monitoring. We’re going to build all of this on top of AWS, but in theory you could also use Azure, Google Cloud or any other cloud provider. It’s important to note that when building your own machine learning platform, you should NOT take these tools for granted. You should evaluate the alternatives – as they may be more appropriate for your specific use case.
Model Template
The first component in our machine learning platform is going to be the model template, which we’re going to build using Cookiecutter for templating, and Poetry for package management. The idea is that when a data scientist starts working on a new project, they will clone our model template (which contains a standard folder structure, Python linting, etc), develop their model, and easily deploy it when it’s ready for production. The machine learning models template will contain basic training and serving code.
Data & Experiment Tracking
The training code in the model template will use the MLFlow client to track experiments. Those experiments will be sent to the MLFlow Server that we’ll run on top of Kubernetes (EKS). The model artifact itself is going to be saved in a S3 Bucket (the Artifact Storage), and metadata about experiments will be saved in a PostgreSQL database. We’ll also track versions of the dataset using DVC, in a S3 bucket.
Model Serving
For model serving, we will build a FastAPI server that’ll be responsible for preprocessing, making predictions, etc. These model servers are going to run on Kubernetes, and we’ll expose them to the internet using Traefik.
Infrastructure as Code
All our infrastructure is going to be deployed using Pulumi, which is an Infrastructure as Code tool similar to Terraform. If you aren’t familiar with the concept, you can read more about it here before continuing. Here are some major advantages of using this method:
Versioned: Your infrastructure is versioned, so if you have a bug you can easily revert it to a previous version.
Code Reviewed: Each change to the infrastructure can be code reviewed and you’re less prone to mistakes.
Sharable: You can easily share infrastructure components, just send the source code for the component.
With Pulumi, you can choose to write your infrastructure in a real programming language, such as TypeScript, Python, C# and more. Even though the natural choice for an ML platform would be Python, I chose TypeScript because at the time of writing this post (July 2021), Pulumi’s implementation of TypeScript is more feature complete.
Repositories & CI/CD
We’re going to have 2 GitHub repositories:
mlplatform-infra – the Pulumi code for the shared infrastructure of the ML Platform. Infrastructure that isn’t model-specific. Kubernetes, MLFlow, S3 buckets, etc.
model-template – the model template code that data scientists can clone, including basic training code, FastAPI server, etc.
Let’s start by setting up Kubernetes with MLFlow server. Create a new GitHub repo called mlplatform-infra. This repo will contain the underlying infrastructure that’s shared between models. Clone it and run:
pulumi new
Open index.ts and write the code for creating a new EKS cluster:
The createOidcProvider is required because MLFlow is going to access the artifact storage (see architecture), which is a S3 bucket, so we need to create a Kubernetes ServiceAccount that can access S3 buckets.
To install packages like MLFlow on Kubernetes, we’re going to use Helm, which is a very popular package manager for Kubernetes. Specifically, we’re going to use the labirras/mlflow Helm chart:
This should install an MLFlow server, but unfortunately it’s not going to work because we still need to connect it to an artifact storage and a model metadata database.
Let’s create an S3 bucket for the artifact storage, and configure MLFlow to use it using the Helm chart’s values:
This should almost work, but there’s one problem: the MLFlow server, which is running on Kubernetes, isn’t going to have access to S3 buckets (see comment above on createOidcProvider).
To fix the permissions issue, let’s create a ServiceAccount that can access S3 buckets and use it:
// Create S3 bucket for MLFlow artifact storageconst artifactStorage =new aws.s3.Bucket("artifact-storage",{acl:"public-read-write",});// Create a k8s ServiceAccount that can access S3 buckets for MLFlowconst mlflowServiceAccount =newS3ServiceAccount('mlflow-service-account',{namespace:"default",oidcProvider: cluster.core.oidcProvider!,readOnly:false,},{provider: cluster.provider });// Install MLFlowconst mlflow =new k8s.helm.v3.Chart("mlflow",{chart:"mlflow",values:{defaultArtifactRoot: artifactStorage.bucket.apply((bucketName:string)=>`s3://${bucketName}`),serviceAccount:{create:false,name: mlflowServiceAccount.name,}},fetchOpts:{repo:"https://larribas.me/helm-charts"},},{provider: cluster.provider });
Finally, we need to set up the Postgres database for model metadata. We’ll use RDS for that:
// Create Postgres database for MLFlowconst dbPassword =new random.RandomPassword('mlplatform-db-password',{length:16,special:false});const db =new aws.rds.Instance('mlflow-db',{allocatedStorage:10,engine:"postgres",engineVersion:"11.10",instanceClass:"db.t3.medium",name:"mlflow",password: dbPassword.result,skipFinalSnapshot:true,username:"postgres",// Make sure EKS has access to this dbvpcSecurityGroupIds: [cluster.clusterSecurityGroup.id, cluster.nodeSecurityGroup.id],});// Install MLFlowconst mlflow =new k8s.helm.v3.Chart("mlflow",{chart:"mlflow",values:{.... backendStore: {postgres:{username: db.username,password: db.password,host: db.address,port: db.port,database:"mlflow"}},},fetchOpts:{repo:"https://larribas.me/helm-charts"},},{provider: cluster.provider });
That’s it, run pulumi up and you should see MLFlow running on your new Kubernetes cluster!
Exposing K8s apps to the Internet using Traefik
Even though MLFlow is running successfully, you have no way of accessing it. Let’s open MLFlow to the internet!
Security Warning
In real life you shouldn’t just expose MLFlow to the Internet of course 🙂 Instead, think of an authentication & authorization mechanisms that work for your organization.
To expose Kubernetes applications to the Internet, we are going to use Traefik – an open-source API gateway. To install Traefik:
In real-life you would want to set up HTTPS and remove HTTP in Traefik’s Helm chart values. In this guide we use HTTP only.
Model Template: Training
Let’s start building our model template. Clone the model-template repo and start a new Poetry package:
poetry new--src my_model
We’ll call it my_model for now, and change to Cookiecutter variables later on. Create a my_model.training package and add your training starting point. Here we’ll use a simple LightGBM example:
from sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_score, log_lossimport pandas as pdimport lightgbm as lgb# Prepare training datadf = pd.read_csv('data/iris.csv')flower_names ={'Setosa':0,'Versicolor':1,'Virginica':2}X = df[['sepal.length','sepal.width','petal.length','petal.width']]y = df['variety'].map(flower_names)X_train, X_test, y_train, y_test =train_test_split(X, y,test_size=0.2,random_state=42)train_data = lgb.Dataset(X_train,label=y_train)defmain():# Train model params ={"objective":"multiclass","num_class":3,"learning_rate":0.2,"metric":"multi_logloss","feature_fraction":0.8,"bagging_fraction":0.9,"seed":42,} model = lgb.train(params, train_data,valid_sets=[train_data])# Evaluate model y_proba = model.predict(X_test) y_pred = y_proba.argmax(axis=1) loss =log_loss(y_test, y_proba) acc =accuracy_score(y_test, y_pred)if __name__ =="__main__":main()
To make it work, you will need to iris.csv dataset from here.
You can also add a Poetry script to make training easy to run. Add this to your pyproject.toml file:
OK, let’s add MLFlow client to this training code. I’ve highlighted the changes:
from sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_score, log_lossimport pandas as pdimport lightgbm as lgbimport mlflowimport mlflow.lightgbm# Enable auto loggingmlflow.set_tracking_uri('http://yourdomain.com/mlflow')mlflow.lightgbm.autolog()# Prepare training datadf = pd.read_csv('data/iris.csv')flower_names ={'Setosa':0,'Versicolor':1,'Virginica':2}X = df[['sepal.length','sepal.width','petal.length','petal.width']]y = df['variety'].map(flower_names)X_train, X_test, y_train, y_test =train_test_split(X, y,test_size=0.2,random_state=42)train_data = lgb.Dataset(X_train,label=y_train)defmain():with mlflow.start_run()as run:# Train model params ={"objective":"multiclass","num_class":3,"learning_rate":0.2,"metric":"multi_logloss","feature_fraction":0.8,"bagging_fraction":0.9,"seed":42,} model = lgb.train(params, train_data,valid_sets=[train_data])# Evaluate model y_proba = model.predict(X_test) y_pred = y_proba.argmax(axis=1) loss =log_loss(y_test, y_proba) acc =accuracy_score(y_test, y_pred)# Log custom metrics if you want mlflow.log_metrics({"log_loss": loss,"accuracy": acc})print("Run ID:", run.info.run_id)if __name__ =="__main__":main()
Try to train the model again and go to your MLFlow server. You should now see the new experiment and download the model file from the browser 🙂
Model Template: Serving
Let’s implement the model server based on FastAPI. Create a my_model.serving package, and create a basic FastAPI server that can make predictions for your basic model. In our case:
Next, let’s create a Pulumi package for the model that can build & push this Docker image to ECR, and deploy it to Kubernetes.
Create an infra directory inside the model template and run pulumi new, as before.
The Pulumi code should look something like:
import*as pulumi from'@pulumi/pulumi';import*as awsx from'@pulumi/awsx';import*as k8s from'@pulumi/kubernetes';import*as kx from'@pulumi/kubernetesx';import TraefikRoute from'./TraefikRoute';const config =new pulumi.Config();const baseStack =new pulumi.StackReference(config.require('baseStackName'))// Connect to the Kubernetes we created in mlplatform-infraconst provider =new k8s.Provider('provider',{kubeconfig: baseStack.requireOutput('kubeconfig'),})// Build & push Docker image to ECRconst image = awsx.ecr.buildAndPushImage('my-model-image',{context:'../',});const podBuilder =new kx.PodBuilder({containers: [{image: image.imageValue,ports:{http:80},env:{'LISTEN_PORT':'80','MLFLOW_TRACKING_URI':'http://yourcompany.com/mlflow','MLFLOW_RUN_ID': config.require('runID'),}}],serviceAccountName: baseStack.requireOutput('modelsServiceAccountName'),});const deployment =new kx.Deployment('my-model-serving',{spec: podBuilder.asDeploymentSpec({replicas:3}) },{ provider });const service = deployment.createService();// Expose model in Traefik newTraefikRoute('my-model',{prefix:'/models/my-model', service,namespace:'default',},{ provider,dependsOn: [service] });
Note that on line 30 we use a special Kubernetes ServiceAccount that can read from S3 buckets. This is similar to the ServiceAccount we created for MLFlow, but it is read-only – you can just copy-paste that piece of code in mlplatform-infra and change readOnly to true.
Model Template: Monitoring
We’ll now set up a data drift monitor using Aporia. For this guide we’ll use Aporia’s cloud. However, Aporia can also be easily installed in your private VPC.
from sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_score, log_lossimport pandas as pdimport lightgbm as lgbimport mlflowimport mlflow.lightgbmimport aporiaaporia.init(token="<YOUR APORIA TOKEN>", environment="local-dev", verbose=True)# ...def main(): with mlflow.start_run() as run: # Train model # ... # Log the new model version to Aporia apr_model = aporia.create_model_version( model_id="my-model", model_version=run.info.run_id, model_type="binary", features=aporia.pandas.infer_schema_from_dataframe(X), predictions=aporia.pandas.infer_schema_from_dataframe(y.to_frame()), ) # Log training set to Aporia # (only aggregations, because it can be huge) apr_model.log_training_set( features=X_train, labels=y_train.to_frame(), ) # Log test set to Aporia # (only aggregations, because it can be huge) apr_model.log_test_set( features=X_test, labels=y_test.to_frame(), predictions=pd.DataFrame(data=y_pred, columns=['variety']), ) print("Run ID:", run.info.run_id)if __name__ == "__main__": main()
We’ll now implement a basic CI/CD pipeline for our model template. This pipeline will run when the data scientist pushes a commit to the main branch. It will deploy the model to our Kubernetes cluster. We’re going to use GitHub Actions for CI/CD, which is GitHub’s native CI/CD system. Our GitHub Action is going to be very simple – all it’s going to do is to run make deploy, and the real deployment logic is going to be implemented in a Makefile. This is useful in case you want to deploy the model from your local computer – for example, if GitHub Actions is down and you need to deploy urgently 🙂 Let’s start by adding the Makefile:
SHELL:=/bin/bashSTACK_NAME=devBASE_STACK_NAME=mlplatform-infra/devPULUMI_CMD=pulumi --non-interactive --stack $(STACK_NAME) --cwd infra/install-deps: curl -fsSL https://get.pulumi.com | sh npm install -C infra/ sudo pip3 install poetry --upgrade poetry installtrain: poetry run traindeploy:$(PULUMI_CMD) stack init $(STACK_NAME) ||true$(PULUMI_CMD) config set aws:region $(AWS_REGION)$(PULUMI_CMD) config set baseStackName $(BASE_STACK_NAME)$(PULUMI_CMD) config set runID $(shell poetry run train | awk '/Run ID/{print $$NF}')$(PULUMI_CMD) up --yes --skip-preview
This Makefile contains 3 commands:
make install-deps
Install Pulumi and its dependencies
Create a virtualenv and install dependencies using Poetry
make train
Train the model
make deploy
Train the model and take the MLFlow Run ID
Run Pulumi with this Run ID to deploy it to the K8s cluster
Next, we’ll create the GitHub Action that deploys the model on push to the main branch. Create .github/workflows/deploy.yml:
It takes AWS credentials and Pulumi access token from GitHub Secrets.
Model Template: DVC Integration
Versioning your data is extremely important – when there’s an issue with your model in production, and you need to debug it, you really want to know how your training set looked like.
If your datasets are super small you could use Git for that. If not, you’ll need some other method to track versions of your datasets. In this guide, we’ll use DVC, which stores your data in an S3 bucket.
First, let’s create an S3 bucket for DVC. In your mlplatform-infra repo, add the following code:
Next, we need to configure our model template to use this DVC repo. Inside the model template run:
cd data/poetry run dvc init --subdirpoetry run dvc remote add --project -d s3 <DVC_BUCKET_URI>
You can fetch the DVC Bucket URI from Pulumi’s outputs:
pulumi stack output dvcBucketURI
pulumi stack output dvcBucketURI
Awesome, we should have DVC configured by now. Let’s add our iris.csv to DVC:
poetry run dvc add ./iris.csvpoetry run dvc push
To make CI/CD work, we need to make sure to pull from DVC before each training. Add that to Makefile:
dvc-pull: poetry run dvc --cd data/ pulltrain: dvc-pull poetry run traindeploy: dvc-pull$(PULUMI_CMD) stack init $(STACK_NAME) ||true$(PULUMI_CMD) config set aws:region $(AWS_REGION)$(PULUMI_CMD) config set baseStackName $(BASE_STACK_NAME)$(PULUMI_CMD) config set runID $(shell poetry run train | awk '/Run ID/{print $$NF}')$(PULUMI_CMD) up --yes --skip-preview
Model Template: Cookiecutter
Cookiecutter allows you to convert our model template to a real template – when the user clones it, he’ll be able to easily change the name of the model, its author, etc.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.



 Alon Gubkin
Alon Gubkin




