

April 7, 2024 - last updated
Model monitoring
Understanding Bias & Fairness in Machine Learning
Machine learning and big data are becoming ever more prevalent, and their impact on society is constantly growing. Numerous industries are increasingly reliant on machine learning algorithms and AI models to make critical decisions that impact both business and individuals every day.
Understanding the concepts of bias and fairness, and how they manifest themselves in data and machine learning can help ensure that you’re practicing responsible AI and governance.
What is ML Fairness?
Today, machine-learning systems are incorporated and integrated into countless industries and businesses that we rely on, including financial institutions, the housing industry, food and beverage, retail, and numerous others. As a result, they must meet both societal and legal standards to make decisions that are fair and inclusive.
But what do we actually mean when we use the term “fair”?
We can determine that we would not want models to be negatively biased on the basis of characteristics such as religion, race, gender, disabilities, and political orientation.
In the simplest form, we can define fairness as equal results achieved for different individuals unless a real justification, in the form of a meaningful distinction, can be drawn between them. In fact, we’re still in the process of defining a whole new vocabulary and set of concepts to talk about fairness.
Why Should We Care About ML Fairness?
Our world would not be a better place if we made decisions based on prejudices and characteristics irrelevant to the decision-making process. If such a world existed, it would only be a matter of time before we, as individuals, became victims of discrimination.
Here are some examples from the last few years of cases in which ML systems were not designed to be biased, but when put into practice, in reality they proved to be biased and harmful to the public:
- COMPAS – Correctional Offender Management Profiling for Alternative Sanctions (COMPAS) is a case management and decision support tool used by U.S. courts to assess the likelihood of a defendant becoming a repeat offender. According to ProPublica, the COMPAS system inaccurately predicted that black defendants posed a higher risk of recidivism than they actually were.
- Amazon Hiring Algorithm – In 2014, Amazon worked on a project to automate the applicant resume review process. Amazon decided to shut down its experimental ML recruiting tool after it was found to be discriminating against women.
- Apple Card – Apple Card is a credit card created by Apple Inc. and issued by Goldman Sachs. It was launched in August 2019. After a few months in use, customers started to complain that the card’s algorithms discriminated against women.
What is Bias in Machine Learning?
There’s an inherent flaw embedded in the essence of machine learning: your system will learn from data, putting it at risk of picking up on human biases that are reflected in that data.
Essentially bias is the phenomenon where the model predicts results that are systematically distorted due to mistaken assumptions. A biased model is a model that produces large losses or errors when we train our model on a training set and evaluate our model on a test set.
What Type of Biases Can Exist in Data?
Protected attributes proxies
Protected attributes are the characteristics or features that by law cannot be discriminated against. It can include age, sex, race, color, sexual orientation, religion, country of origin, marital status, and many more.
Even when the protected attributes don’t appear in the data sets used for the ML model, it might still exist through proxies – attributes with statistical relation to protected attributes.
Biased Labels
The training set used to train the ML model can be labeled by humans who may have been biased during the tagging process. For example, in a system that predicts the success rate of a job candidate, if the labeling was done by a person who is biased (intentionally or unintentionally), the ML model will learn the bias that exists in the labeled data set it receives.
Biased Sampling
If the model already has an initial bias, it could lead to bias degradation over time. This can occur if the data set used to train the model relies on decisions made by the tainted model.
IImagine a “Hiring HR” ML model biased towards male applicants. If the model is discriminatory, fewer female applicants will be hired. Even if there are higher success rates for hired female applicants, after the model processes the input data, there will be fewer samples from the discriminated population, and as a result fewer women will be considered for employment.

Limited data
There are instances when the data collected from a specific population segment is limited, e.g., when only a limited amount of learning data has been collected or when some features of the discriminated population segment are missing. This can lead to the model being inadequate for predicting that population.
How to Avoid Model Bias and Ensure Fairness?
Unfortunately, there is no magic solution. In fact, ML fairness is a complicated problem. To begin with, there is no consensus for fairness definitions or metrics. Additionally, the key to preventing unfair practices is a process rather than a specific action item.
Be aware. Take an active approach.
The good news is if you read this post, you already completed the first initial step towards achieving fairness in your AI. Be aware of the pitfalls. But don’t stop here!
Take ML fairness into consideration from the beginning, at the research stage of every ML project.
- Set concrete goals for fairness
- Consider the target audience of the ML project
- Identify the parties that might be potentially discriminated against
- Design metrics & algorithms to be used in order to reflect fairness issues and goals
- Find other similar use cases and pitfalls from the past
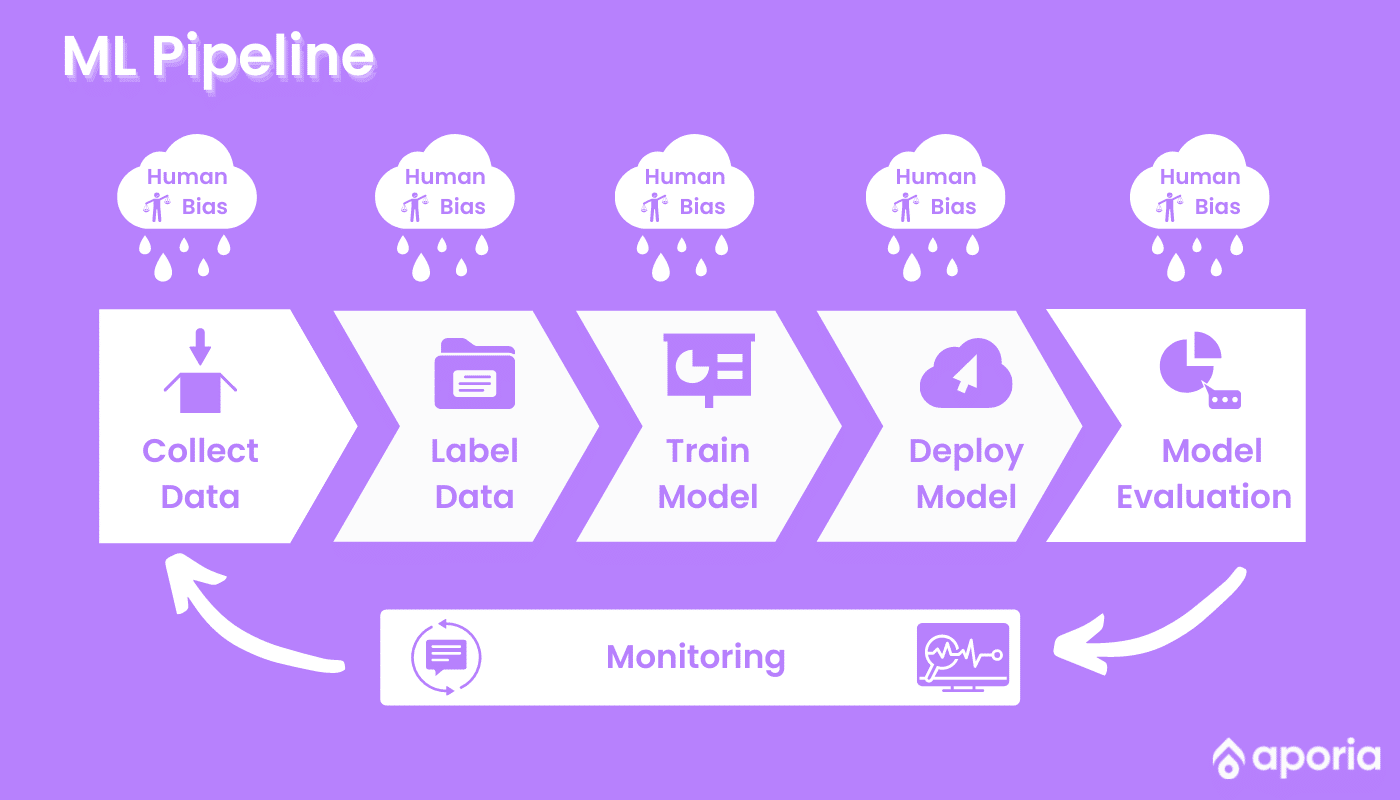
Treatment in 4 Main Cross-sections
Data Mining
In the data mining step, it’s important to measure the data distributions according to one or more protected attributes. It should be a priority to define metrics for the representativeness of the data and make sure that there is enough data and labels for minority groups.
Pay attention to your goals. The desired distribution of a subgroup doesn’t necessarily need to correspond to the population. In many cases, improving the model’s performance on a minority subgroup requires oversampling from that group.
Model Training
Define the metrics and measurement methods for fairness issues and bias in your team’s model. Use these measures during model training.Following this practice during training may allow you to choose hyperparameters to enable a good balance of fairness and performance.
Post-processing
Measure the fairness metrics on the test dataset as well! Compare the distribution of the predicted values across different subgroups. Also, compare performance metrics (such as accuracy, confusion matrix, RMSE, etc…) of different protected groups.
Serving to Monitor
It is essential to measure and monitor the fairness metrics in production, in the real world. This step is extremely important as it will enable quick detection and mitigation of fairness issues (such as prediction drift with respect to fairness). There are a number of tools you can use to reduce the risk of ML bias and ensure fairness, including Aporia’s customizable ML monitoring solution.
Detect Bias and Ensure Fairness with ML Model Monitoring
Building a machine learning model often requires using generalization techniques. These deduction techniques often improve your model’s performance, however, sometimes it does so at the expense of certain populations, by relying on characteristics such as religion, race, gender, disabilities, and political orientation. As data scientists, we have a responsibility to monitor our models and improve them as necessary, to prevent that from happening. So remember to consider bias and fairness the next time your machine learning model is deployed into production.
If you don’t already have a solution in place, we welcome you to book a demo with our team to learn how to start monitoring your models for bias and ensure responsible AI.
