

April 7, 2024 - last updated
Machine Learning
Machine Learning Models: 4 Real Life Challenges and Solutions
What Is a Machine Learning Model?
A machine learning model is a program that finds patterns and makes decisions in new datasets, based on observations from previous datasets.
For example, in natural language processing, machine learning models can parse and correctly identify the intent behind previously unheard-of sentences and word combinations, or even generate new text. In image recognition, machine learning models can be taught to recognize objects such as cars and dogs, or even create novel photorealistic images.
Machine learning models are typically “trained” on large datasets to perform these tasks. During training, machine learning algorithms are optimized to look for specific patterns or outputs in the dataset, depending on the task. The output of this process, usually a computer program with specific rules and data structures, is called a machine learning model. The model can be applied to new data and provide predictions, a process known as inference.
Types of Machine Learning Models
Supervised Learning
The dataset contains examples of inputs and desired outputs or labels, so that the machine learning model can compute the error for a particular prediction. The goal of supervised learning is to create functions that efficiently generalize from training data to unseen data.
Unsupervised Learning
Sometimes there is no way to create a supervised model, for example, because the dataset does not include the desired output. Unsupervised learning divides the dataset into classes, where each class contains segments of the dataset with common features. Unsupervised learning aims to build mapping functions that classify data based on features.
Semi-supervised Learning
This machine learning approach is a mix of the two types above. Data scientists can provide training data and labeling algorithms, but models can also explore the data based on its intrinsic patterns, without relying on training examples. This is useful when labeled training data is limited.
Reinforcement Learning
Reinforcement learning is a type of machine learning algorithm that can be given a set of tasks, parameters, and final values. Reinforcement learning algorithms define rules to explore different options and possibilities, monitoring and evaluating each option to determine the best outcome. The algorithm learns by trial and error. Based on past experiences, it adjusts its approach to new situations for best results.
What Is Machine Learning Classification?
Classification is defined as the process of recognizing, understanding, and grouping entities into discrete categories known as “classes”. With the help of pre-classified training datasets or unsupervised clustering algorithms, classification programs use algorithms to process unseen datasets, and classify them into the most relevant classes.
Typically, classification algorithms evaluate input data and predict the probability that it belongs to each of the classes.
Learn more in our detailed guide to machine learning classification (coming soon)
4 Real Life Challenges of Machine Learning Models
1. Data Collection
The first step in a machine learning project is to find and collect data assets to enable model training. However, finding data of sufficient quality and quantity is one of the most common challenges facing data scientists. This directly impacts their ability to build robust ML models.
There are two primary reasons it is so difficult to collect data for ML models:
- Unqualified data collection—organizations collect a lot of data without taking action to determine whether it is useful or not. It is often assumed that more data can provide more insights, and there is widespread availability of low-cost data storage. This results in large volumes of data that often does more harm than good.
- Data richness—as organizations continue to collect data from so many applications and tools, the number of data sources that data scientists must integrate and evaluate continues to grow. Integrating data from various semi-structured sources is a complex process.
2. Machine Learning Bias and Fairness
Bias is a systematic error in a machine learning model. Common causes of bias are incorrect assumptions made in the training process, not enough training examples, and insufficient data about edge cases.
Bias issues can also result from real-world biases, such as real-world inequality between genders or races, manifested in the training data. This can result in a fairness problem – a model can learn from biases in its training data and make prejudiced decisions against certain groups or individuals.
Technically, bias is defined as the error between the mean model prediction and the correct answer. High bias models are unable to identify appropriate data trends, run the risk of over-generalizing the training data, have a high error rate, and might represent compliance issues.
Learn more in our detailed guide to machine learning bias.
3. Machine Learning Inference
Machine learning (ML) inference is the process of running real-time data points with a machine learning algorithm to compute an output. ML models are typically built of software code that implements mathematical algorithms, so machine learning inference essentially requires deploying a software application to a production environment.
ML inference tasks are sometimes incorrectly assigned to data scientists. Data scientists typically do not have expertise in DevOps or engineering, and may not be able to successfully deploy models.
Additionally, DevOps and data engineers are often unable to support deployments, because they have other priorities and may not understand what ML inference requires. ML models are often written in languages like Python, and leverage technologies that DevOps teams are less familiar with.
To deploy a model to production, engineers typically need to take Python code and run it on the available infrastructure. Deploying an ML model also requires additional coding to map the input data into a format accepted by the ML model, which adds to the burden on engineers when deploying the ML model.
Learn more in our detailed guide to machine learning inference.
4. Data Security and Privacy
Privacy concerns and growing compliance requirements make it even more difficult for data scientists to make use of datasets. In addition, migration to cloud environments and the increasing complexity of IT environments has made cyberattacks more common in recent years.
Ensuring continued security and compliance with data protection regulations such as the GDPR presents an additional challenge for organizations. Failure to do so could result in severe financial penalties, reputational damage, and costly audits.
Addressing the Challenges
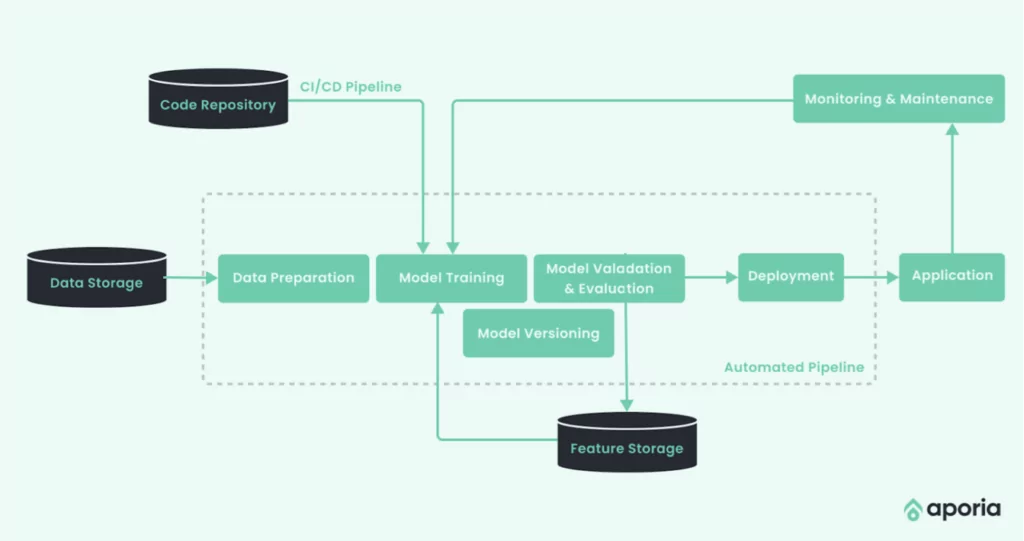
Machine Learning Model Monitoring (ML Monitoring)
ML monitoring involves observing models deployed in production to ensure reliable performance. Many aspects can affect a model’s performance and require monitoring, including broken data pipelines and real-world changes that affect the content and shape of data fed to the model.
Any changes in the feature vector are reflected in the model’s performance and can result in different predictions than those the model was trained to generate. However, some problems might take a long time to surface, and ML models exist in a complex world full of moving parts that constantly change and impact their performance.
Without monitoring, ML models might underperform without your knowledge and without any ability to identify the cause. A monitoring platform enables you to achieve full visibility into ML models and detect production issues early on. It helps detect model instability issues, learn how and why the model is performing poorly, diagnose specific issues and resolve them.
Learn more in our detailed guides to:
Traditional Software Testing for Machine Learning Models
To fully operationalize ML models, teams should follow traditional software testing best practices, alongside ML model monitoring. Here is how to apply the three main types of tests used in software development to an ML model:
- Unit tests—check the correctness of the code used to build the ML pipeline.
- Regression tests—check if the model breaks after a change, and identify if previously known errors are recurring.
- Integration tests—verify that the different components of the machine learning pipeline interact properly with each other.
Each of these test types can be broken down into different functional areas of the model—for example, model evaluation, testing, validation, or inference. This can improve reliability and robustness of ML pipelines and the underlying model code.
ML Model Governance
AI/ML model governance is the overall process of how organizations control access, enforce policies, and track models and their output. Effective model governance can protect the organization against both financial and reputational loss, and is important for regulatory compliance. By implementing a robust governance program, you can minimize organizational risk from AI/ML models during compliance audits.
AI/ML model governance includes:
- Setting access controls for all models in production
- Managing all model versions
- Generating appropriate documentation
- Continuously monitoring models their outputs
- Enforcing existing IT policies in machine learning programs
Organizations that effectively implement all the above components not only reduce risk, but gain operational efficiencies that help them increase the return on investment of AI initiatives. Governance ensures there is logging, monitoring, versioning, and access control for models, enabling more granular control over how they behave in production. This makes it possible to control model inputs and eliminate any variables that could adversely affect business results.
Learn more in our detailed guide on model governance
Machine Learning Optimization Techniques
The main objective of machine learning is to build models that accurately predict a particular set of outcomes. Machine learning optimization is essential for ensuring an effective, performant model.
Machine learning optimization involves adjusting hyperparameters to minimize cost functions using optimization techniques. A cost function describes the difference between the model’s prediction and the parameter’s true value.
Optimization happens in two steps:
- Setting hyperparameters before the model training process. These describe the model’s structure.
- Setting model parameters during training. These include internal model data like weights and biases.
Hyperparameter optimization tunes the model by finding an optimal combination of values to reduce error. Here are some techniques for optimizing an ML model’s hyperparameters.
Exhaustive Search
Exhaustive search, also known as brute force search, involves assessing the best match when looking for optimal hyperparameters. The number of possible options in machine learning is usually large. However, this can be slow when you have thousands of options to consider, making it inefficient for many use cases.
Gradient Descent
This algorithm is the most common optimization method to minimize error. It requires iterating over the training dataset to re-adjust the model. The objective is to minimize cost functions, achieve the smallest possible error, and improve model accuracy.
The above graph graphically represents the gradient descent algorithm’s path through the variable space.
You start with a random point and choose an arbitrary direction to see if the error increases, indicating a wrong direction. If you cannot continue decreasing the error, it suggests you’ve reached the local minimum. However, the gradient descent doesn’t work well if multiple local minimums exist.
Gradient descent involves same-sized steps—if your chosen learning rate is too large, the algorithm’s accuracy might be affected. On the other hand, if the learning rate is too low, the algorithm becomes inefficient.
Genetic Algorithms
Genetic algorithms are an ML optimization method that is inspired by evolution theory (i.e., it is a “survival of the fittest” algorithm). The population is a random selection of algorithms with different adjustment levels. You calculate each model’s accuracy and keep the ones that perform best. Next, you create a new generation of algorithms using similar hyperparameters to the strongest models.
Here is an illustration of this logic:
This process repeats multiple times until the data scientists, researcher, or engineer finds the best model. This makes it possible to optimize an ML model beyond local minimums and maximums. Genetic algorithms are popular for neural network optimization.
Related content: Read our guide to machine learning tutorial
Monitoring Machine Learning Models with Aporia
Aporia is a full-stack, customizable machine learning observability platform that empowers data science and ML teams to trust their AI and act on Responsible AI principles. When a machine learning model starts interacting with the real world, making real predictions for real people and businesses, there are various triggers – like drift and model degradation – that can send your model spiraling out of control. Aporia is the best solution to ensure your ML models are optimized, working as intended, and showcasing value for the business.
Aporia fits naturally into your existing workflow and seamlessly integrates with your existing ML infrastructure. Aporia delivers key features and tools for data science teams, ML teams, and business stakeholders to visualize, centralize, and improve their models in production:
Visibility
- Single pane of glass visibility into all production models. Customizable dashboards that can be understood and accessed by all relevant stakeholders.
- Track model performance and health in one place
- Customizable metrics and widgets to ensure you see everything you need.
- Start monitoring in minutes.
- Instant alerts and advanced workflows trigger.
- Customizable monitors to detect drift, model degradation, performance, etc.
- Choose from our automated monitors or dive deep into our code-based monitor options.
- Get human-readable insight into your model predictions.
- Simulate ‘What if?’ situations. Play with different features and find how they impact predictions.
- Communicate predictions to relevant stakeholders and customers.
Root Cause Investigation
- Drill down into model performance, data segments, and data stats or distribution.
- Find and debug issues.
- Explore and understand connections in your data.
To get a hands-on feel for Aporia’s ML monitoring solution, we recommend:
- Trying out our Free Community Edition
- If you’re ready for a personal guided tour, Book A Demo and someone from our team will reach out shortly.
See Additional Guides on Key Machine Learning Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of machine learning.
Auto Image Crop
Authored by Cloudinary
- Auto Image Crop: Use Cases, Features, and Best Practices
- 5 Ways to Crop Images in HTML/CSS
- Cropping Images in JavaScript
Advanced Threat Protection
Authored by Cynet
- What is Network Analytics? From Detection to Active Prevention
- 7 Cyber Security Frameworks You Must Know About
- Threat Hunting: 3 Types and 4 Critical Best Practices
Multi GPU
Authored by Run.AI
- Multi GPU: An In-Depth Look
- PyTorch Multi GPU: 3 Techniques Explained
- 6 Reasons for Low GPU Utilization and How to Improve It
