

April 7, 2024 - last updated
MLOps
Ultimate Guide to MLOps: Process, Maturity Path and Best Practices
What is Machine Learning Operations (MLOps)?
Machine learning (ML) models can provide valuable insights, but to be effective, they need to continuously access and efficiently analyze an organization’s data assets. Machine Learning Operations (MLOps) is a set of tools, methodologies, and processes that enable organizations to build and run ML models efficiently.
MLOps is a cross-functional, iterative process that helps organizations build and operate data science systems. It lends from DevOps practices, treating machine learning (ML) models as reusable software artifacts. This allows models to be deployed and continuously monitored in a repeatable process.
MLOps supports continuous integration (CI), and rapid, automated deployment for ML models. To address the problem of model drift and data drift, it performs continuous monitoring and retraining of models, based on performance metrics in production environments, to ensure they perform optimally as data and context change over time.
Why is MLOps Important?
Here are the main issues and bottlenecks facing ML projects, which MLOps practices can help address:
- Skills shortage—there is a shortage of data scientists and machine learning engineers. This makes it especially important to adopt automation and efficient practices that can reduce manual labor, allowing data science teams to focus on innovative algorithms and high quality datasets.
- Adapting to change—keeping up with evolving business requirements can be difficult. Data flowing into models also constantly changes (this is known as data drift). Maintaining ML models, monitoring their performance, and continuously retraining and updating them to meet these requirements is challenging. MLOps creates a repeatable process that makes it painless to update ML models and redeploy them to production.
- Collaboration—the inability to find common ground for communication between all stakeholders in an ML project, including data scientists, operations staff, and business leaders, can be a major obstacle for AI initiatives. MLOps is a collaborative work process that can solve this problem.
DevOps vs MLOps
DevOps and MLOps have many similarities, because the MLOps process was derived from DevOps principles. But there are a few key differences:
- Experimentation—MLOps is more focused on experimentation than DevOps. ML teams have to tune hyperparameters, parameters, data, and models, while tracking their experiments to ensure reproducible results.
- Testing—in a DevOps environment, testing involves verifying that software performs the desired functionality and meets basic requirements like performance and security. This is carried out via unit testing, integration testing, and end-to-end or system testing. In a MLOps system, tests are required, but in addition, models need to be trained, tested, and evaluated to identify their performance. This makes testing more complex.
- Automated deployment—MLOps teams require more stages, coordination, and automated processes to deploy an ML model (compared to a traditional software release). This requires a multi-step pipeline that can retrain the model, evaluate it, and monitor its real-life performance—automating steps the data scientists do manually.
- Production monitoring—DevOps teams monitor basic operational criteria like uptime and latency, and do not expect a system to degrade in performance as a normal part of its lifecycle. However, MLOps teams expect performance degradation of ML models. Models often perform worse in production than they do in training, due to differences between training data and real-life data inputs. They can also decay over time, due to phenomena like data drift and concept drift.
- CI/CD/CT—in a DevOps environment, there is a CI/CD pipeline that focuses on testing and validating code and software artifacts, deploying it to production, and ensuring it works as expected. In ML, the pipeline must deal with additional concerns, including validating data, data schemas, models, and their performance. Continuous testing (CT) is a new element in the MLOps pipeline, which automatically retrains and serves models based on inputs from the production environment.
MLOps vs AIOps
While commonly confused, MLOps and AIOps are two distinct fields:
- MLOps is a way to deploy ML systems and standardize processes to improve outcomes for AI initiatives.
- AIOps is an approach to IT system automation that uses ML and big data.
The problem solved by AIOps is that organizations are generating huge volumes of operational data, and it is increasingly difficult to identify risks and alert staff to resolve them. AIOps technology can identify issues, and automatically resolve recurring issues, without requiring staff to manually monitor processes.
AIOps combines big data and machine learning to automate IT operational processes such as event correlation, anomaly detection, and causality determination. This can provide insights and predictive analytics to help IT operations effectively respond to operational problems.
What Are the Components of MLOps Architecture?
Let’s review the basic building blocks and workflow of an MLOps process. These are illustrated in the diagram below.
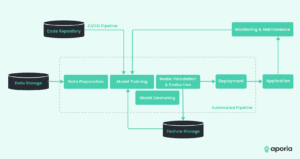
The process works as follows:
- The pipeline fetches data from storage—this triggers the data preparation process, which includes data cleaning, validation, and formatting. Data is now in a form that can be used to train the ML model.
- CI/CD pipeline—model code is validated, built, and deployed via a continuous integration and development (CI/CD) pipeline. The automated pipeline ingests data prepared in the previous step and triggers the model training process. Automated testing and checks are performed to ensure that the model is suitable for deployment and its performance meets minimum thresholds.
- Model evaluation—the model is evaluated to identify its successful, well-performing features. These are moved to a feature repository and can be used to train future models.
- Model deployment—after successful validation and evaluation of the model, the model is automatically moved to deployment and used for inference in production. Finally, the new model is saved to version control. This makes it possible to track model versions and revert to previous versions if necessary.
- Automated monitoring—during the model’s lifespan, monitoring ensures that everything is working as expected, identifies performance issues and drift, and allows for quick maintenance in case of problems.
In a full MLOps pipeline, all steps in the process are automatic, but can be optionally stopped by operators at any time for manual evaluation, or extended with specific steps required by the organization. The pipeline can be activated on several triggers—when new data is available for retraining, when the model is updated, or when performance issues are discovered in a production model.
Three Levels of MLOps Maturity
This discussion is based on the MLOps maturity model published by Google Cloud.
MLOps Level 0: Manual Process
In a manual MLOps process, every step is manual, from initial data analysis through preparation, training, and validation. There is a disconnect between ML and operations teams—data scientists build a model and hand it off to operations teams who must figure out how to deploy it.
Because of the difficulty of creating and deploying new versions of a model, releases happen infrequently, usually only 2-4 times per year.
In this manual process, there is no continuous integration (CI) system, meaning that model code is written in notebook systems and either shared as files or committed to source control. There is also no continuous deployment (CD), meaning that deployment is performed manually. Model deployment is only concerned with the prediction service (typically a REST API), not the entire MLOps system, and there is no active production monitoring.
MLOps Level 1: ML Pipeline Automation
At this level of maturity, the following improvements are added:
- Rapid experiments—experimentation is automated, making it possible to run more experiments and move them easily to production.
- Continuous testing—automatically training the model in production using fresh data from the pipeline.
- Consistency between experiments and operational environments—experiments are designed in a way that makes it easy to reproduce and transfer them to production.
- Continuous delivery—the pipeline continuously receives new versions of the model, retrains them, and deploys to production.
- Deploying the entire pipeline—“deployment” is no longer concerned only with the inference service. Instead, the entire training pipeline is deployed in each iteration.
MLOps Level 2: CI/CD Pipeline Automation
At this level of maturity, the following improvements are added:
- A robust automated CI/CD system—this allows data scientists to rapidly try new ideas related to model features, architecture, and hyperparameters. With every change, the entire pipeline can easily be rebuilt, tested, and deployed.
- Comprehensive MLOps pipeline—the pipeline includes source control, test and build services, deployment, a model registry, a feature store, a metadata store, and a pipeline orchestrator.
- Redeployment based on monitoring—production monitoring based on live monitoring can automatically trigger a new experimentation cycle and redeployment of the pipeline.
MLOps in the Cloud
MLOps can be hosted on-premises and in the cloud, and each has its own advantages:
- Cloud-based MLOps give you access to a variety of computing, data, and AI services. These managed services can run MLOps processes in the cloud and provide the elastic computing capacity ML projects need, without having to set up, configure, and scale those resources in-house.
- On-premise MLOps provides a high level of flexibility and customization, and makes it easier to integrate the MLOps pipeline with legacy systems. However, it can require a major investment and significant expertise to set up a full MLOps pipeline in house. In addition, scaling to meet future requirements is a major challenge.
All three major cloud providers offer MLOps platforms that can help organizations of all sizes manage an ML pipeline in the cloud:
- Amazon SageMaker is an ML platform that helps build, train, manage, and deploy machine learning models in production-ready ML environments. SageMaker accelerates experiments with specialized tools for labeling, data preparation, model training, tuning, monitoring, and more.
- Azure ML is a cloud-based platform for training, deploying, automating, managing, and monitoring machine learning experiments. It supports both supervised and unsupervised learning.
- Google Cloud offers an end-to-end fully managed platform for machine learning and data science. It provides an ML workflow that supports the work of developers, scientists, and data engineers, with many features for pipeline automation and machine learning lifecycle management.
Related content: Read our guide to Azure MLOps (coming soon)
Challenges of MLOps Implementation
Limited Computing Resources
One of the biggest barriers to implementing MLOps is the lack of computing power. Machine learning algorithms require a lot of resources to run. On-premises systems often struggle to adequately meet these compute requirements for large-scale ML projects.
Another issue is that the MLOps process requires training models multiple times for automated training, testing and evaluation of every model iteration—this increases computational requirements by an order of magnitude.
A natural solution for this problem is the computing power provided by cloud platforms. Cloud providers offer elastically scalable resources, which can automatically provision enough computing power to perform all tasks required by an ML project, from data preparation to model training to model inference. Most MLOps programs rely on the use of cloud-native solutions.
No Unified Data Store and No Central Governance
Machine learning algorithms require large amounts of data to obtain high-quality results. However, many organizations retrieve input data for ML algorithms from siloed data stored in different locations and formats.
To make data usable for ML, organizations need a data platform that can ingest data in multiple formats, both structured and unstructured, store it in a central repository, pre-process and normalize it to enable consistent analysis, and apply data security and governance to protect sensitive data.
Related content: Read our guide to AI governance (coming soon)
Integration Challenges
ML projects must integrate multiple technologies, including data processing, machine learning and deep learning frameworks, CI/CD automation tools, monitoring and observability tools, and more. Creating a cohesive MLOps pipeline is a challenge.
Several cloud providers offer an all-in-one MLOps platform that deals with everything from data ingestion through to final model deployment. This can solve the integration challenge, but it also requires locking into a specific cloud vendor, and might be difficult to customize to the organization’s specific requirements.
3 Tips for Successful MLOps
1. Automate Everything
Simply put, more advanced automation increases an organization’s MLOps maturity and will probably lead to better results.
In an environment without MLOps, much of the work of machine learning systems is done manually. These tasks include cleaning and transforming data, engineering features, partitioning training, testing data, writing model training code, and more. This manual effort leaves room for error and wastes the valuable time of data science teams.
One example of automation that can reduce manual labor is retraining—an MLOps pipeline can automatically perform data collection, validation of the model on the new data, experimentation, feature engineering, model testing and evaluation, with no human intervention. Continuous retraining is considered one of the first steps in automating machine learning.
By automating more and more stages of the ML workflow, an organization can eventually reach a fully streamlined ML development process that enables rapid iteration and feedback, in line with agile and DevOps principles.
2. Prioritize Experimentation and Tracking
Experiments are a crucial part of the ML process. Data scientists experiment with data sets, features, machine learning models, and hyperparameters. In this process, it is important to track each iteration of the experiment to finding the best combination of criteria that can improve model performance.
Traditionally, data scientists ran experiments using notebook platforms, often running on their local machine, manually tracking model parameters and details. They would often need to wait for models to train, due to limited computing resources, and there was no central way to log and share experiment results, leading to errors, inconsistencies, and duplicate work.
While Git can be used to perform version control for model code, it cannot easily be used to log the results of experiments data scientists perform. This requires the concept of a model registry—a central repository of ML models which can track performance and other changes across multiple ML models and many different variations of the same model.
Rapid experimentation, with consistent tracking of experiments, allows MLOps teams to identify successful models, roll back models that are not performing well, make results reproducible, and provide a complete audit trail of the experimentation process. This significantly reduces manual work for data scientists, freeing up more time for real experimentation.
3. Embrace Organizational Change
To achieve a mature MLOps pipeline, organizations must evolve. This requires process changes that encourage collaboration between teams, breaking down silos. In some cases, the entire team needs to be restructured to promote MLOps principles.
In less mature data science environments, data scientists, engineers, and software engineers often work independently. As maturity increases, all members of the team must work as a cohesive unit. Data scientists and engineers must work together to turn experimental code into repeatable pipelines, and software and data engineers must work together to automatically integrate models into application code.
More collaboration means less reliance on any one person throughout the deployment. Teamwork, combined with automated tooling, can help reduce expensive manual work. Collaboration is key to achieving the level of automation required for a mature MLOps program.
MLOps with Aporia
Aporia is a full-stack, customizable machine learning observability platform that empowers data science and ML teams to trust their AI and act on Responsible AI principles. When a machine learning model starts interacting with the real world, making real predictions for real people and businesses, there are various triggers – like drift and performance and model degradation – that can send your model spiraling out of control.
Our ML observability platform is the ideal partner for Data Scientists and ML engineers to visualize, monitor, explain, and improve ML models in production in minutes. The platform supports any use case and fits naturally into your existing ML stack alongside your favorite MLOps tools. We empower organizations with key features and tools to ensure high model performance:
Production Visibility
- Single pane of glass visibility into all production models. Customizable dashboards that can be understood and accessed by all relevant stakeholders.
- Track model performance and health in one place
- Customizable metrics and widgets to ensure you see everything you need.
- Start monitoring in minutes.
- Instant alerts and advanced workflows trigger.
- Customizable monitors to detect drift, model degradation, performance, etc.
- Choose from our automated monitors or dive deep into our code-based monitor options.
- Get human-readable insight into your model predictions.
- Simulate ‘What if?’ situations. Play with different features and find how they impact predictions.
- Communicate predictions to relevant stakeholders and customers.
Root Cause Investigation
- Drill down into model performance, data segments, data stats or distribution.
- Detect and debug issues.
- Explore and understand connections in your data.
To get a hands-on feel for Aporia’s ML monitoring solution, we recommend:
- Start a Free Trial and see Aporia’s ML observability in action.
- If you’re ready for a personal guided tour, Book A Demo and someone from our team will reach out shortly.
-
See Additional Guides on Key Machine Learning Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of machine learning.
Auto Image Crop
Authored by Cloudinary
- Auto Image Crop: Use Cases, Features, and Best Practices
- 5 Ways to Crop Images in HTML/CSS
- Cropping Images in JavaScript
Advanced Threat Protection
Authored by Cynet
- What is Network Analytics? From Detection to Active Prevention
- 7 Cyber Security Frameworks You Must Know About
- Threat Hunting: 3 Types and 4 Critical Best Practices
Multi GPU
Authored by Run.AI
