It goes without saying that AI is providing invaluable tools that are now becoming a prevalent part of our lives. But at the same, it is becoming increasingly dangerous. With risks of hallucinations, misinformation, private data being leaked, and even being responsible for the suicide of a teenager, more questions are being raised about the level of oversight companies have over these chatbot tools.
Oversight comes in the form of guardrails. With the new EU AI Act coming into force, and countries beginning to pass mandatory laws about the usage of guardrails, the world is quickly understanding that AI alone cannot be trusted. There needs to be an additional oversight that can verify what is happening at all times.
Guardrails come in many forms, from LLM-as-a-Judge, to human-as-a-judge, and fine-tuned SLMs guardrails. We strongly believe that guardrails built on SLMs is the superior method to enforcing behavior, as they provide the highest level of accuracy, and fastest latency, as proved through Aporia’s mutliSLM Detection Engine.
What is an SLM?
While LLMs – large language models – may be capturing the most headlines, it isn’t surprising to know that there are also SLMs – small language models. An SLM is simply a smaller version of an LLM, containing significantly fewer parameters than an LLM. While LLMs contain billions or trillions of parameters, SLMs may contain only a few million.
The differences between SLMs and LLMs
Generally, SLMs can do the same things as LLMs, just to different levels. While LLMs have significantly more parameters, they have the ability to generate human-like responses and to closely mimic human language. SLMs are also able to provide conversational responses to text, and if properly tuned, can also create human-like text. However SLMs are significantly smaller than LLMs, meaning they are unable to generate the same quality of text as LLMs.
SLMs vs LLM-as-a-Judge
When considering AI oversight, there are several methods that are being used in order to prevent security and reliability issues from occurring, which inevitably cause a lack of trust and risk of legal implications.
The first method we will consider is LLM-as-a-Judge, the most commonly used method for AI guardrails.
LLM-as-a-Judge: Single Prompts
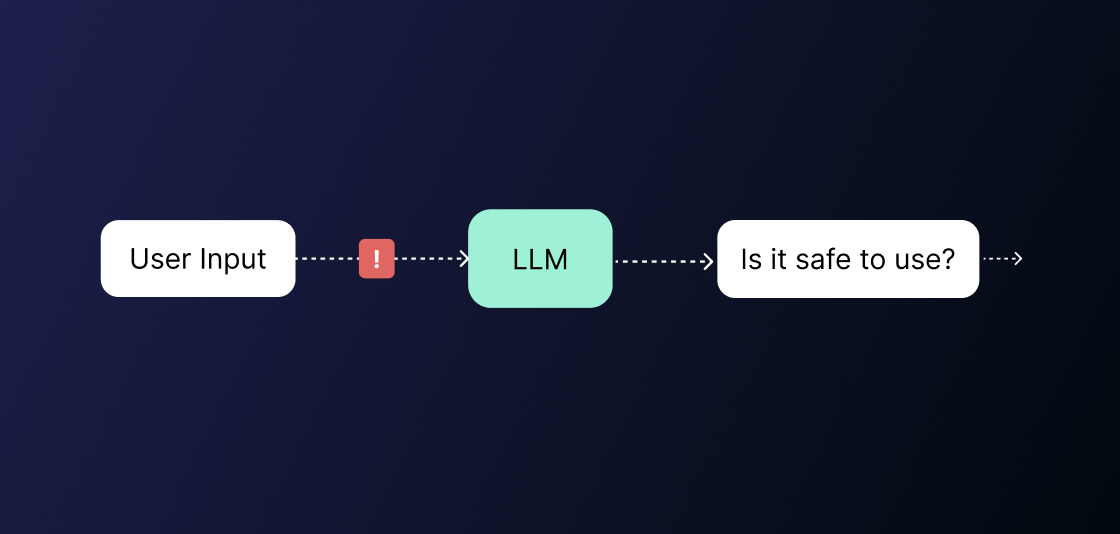
In this version of AI oversight, an LLM is placed in between the AI and the user, and evaluates messages based on specific criteria. See the diagram below, a user messages, these messages run through a single prompt which is transferred through the LLM. The LLM then responds as to whether the user input is safe or unsafe. The more tasks the LLM is given, the longer the prompt is.
Limitations of LLM-as-a-Judge
There are limitations to this method, however. The main one is that LLMs struggle to comprehend and deal with multiple tasks at once. Asking the LLM ‘does this message contain a hallucination’ is far easier dealt with than asking ‘does this message contain a hallucination, prompt injection, PII and toxicity’ is far more difficult for the LLM to comprehend.
Think of the LLM as a young child. Asking a child to do a single task, such as ‘collect your book’ is more likely to be carried out over asking the child ‘collect your book, bring it to the table, sit down, and turn to page 10’.
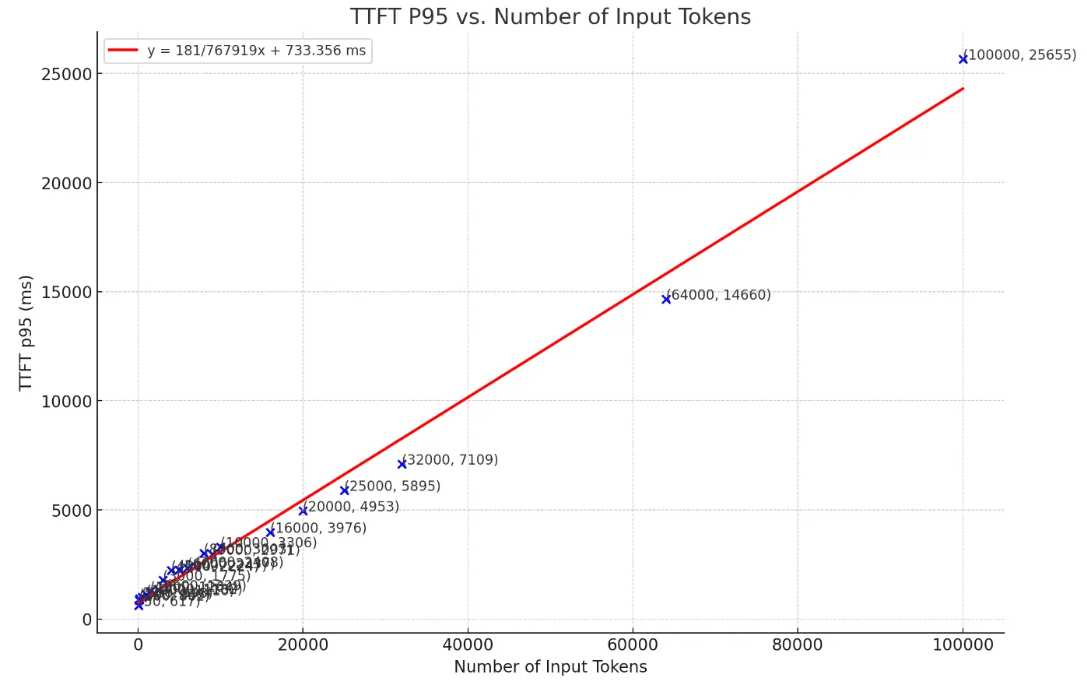
A study was carried out by Glean that shows how input token count impacts the latency of AI tools. They discovered a direct correlation between the number of input tokens and TTFT (time to first token). As the number of tokens increased, so did the TTFT. On top of that, they noticed that the relationship was linear. They came to the conclusion this likely due to the fact that Transformers mask the unpopulated values in the context window vector with zeros, allowing the GPUs to skip part of the matrix multiplication.
So not only does the TTFT increase when the number of tokens increases, but the LLM is probably ignoring part of the input that it was sent – similar to that young child example above – leading to less accurate results at the same time.
When implementing guardrails to oversee your AI, there are 2 principles you want to make adhere to:
The guardrails are nearly 100% accurate in their detections
The guardrails are working at super-fast latencies
Using this LLM-as-a-Judge method for your guardrails does not check off any of these principles. It is slow in latency and has low accuracy, and the latency gets considerably worse with an increased amount of tokens in the prompt.
LLM-as-a-Judge: Parallel Prompts
In response to the latency and accuracy issues of the LLM-as-a-Judge, some companies came up with a solution that involves splitting up the prompt into separate prompts and running them through the LLM. In this way, the LLM needs to deal with many shorter prompts, which means the accuracy of LLM response is significantly increased.
In this diagram, you can see the user input comes in, and this input is split into several queries. These queries are individual prompts, which run through the LLM to receive an output.
The downfalls of this LLM-as-a-Judge architecture
While this architecture may lead to higher accuracy compared to the aforementioned architecture, thanks to the splitting up of tasks into individual prompts, there are several downfalls to this approach.
The most important one being that the cost to build this type of architecture is very expensive due to the increased amount of tokens, which can be a burden on an organization. With this approach, a much larger number of tokens are being used, as the same input is being sent to the LLM multiple times over, with very specific instructions for each task.
In addition to the cost, the latency isn’t necessarily improved with this approach. This approach entails multiple parallel requests to the LLM, but the overall time is as slow as the slowest query. Queries to publically served LLMs have variations and spikes in the latency, so the more queries you have, the more likely you are to increase the latency.
Aporia carried out a test to see the latency and accuracy of GPT-4o and Nvidia/NeMo guardrails vs. Aporia’s multiSLM Detection Engine, and we saw a massive jump in latency and accuracy. We reveal the results later on in the piece.
LLM-as-a-Judge compared to Human-as-a-Judge
Another traditional method for AI oversight is human-as-a-judge, which involves physical human intervention, such as through domain experts manually assessing the quality of the model’s outputs. Another option could be through conducting controlled experiments and collecting user feedback.
However, this method is not only expensive and time-consuming, but it doesn’t provide real-time feedback on the AI’s responses or user messages. This means that any prompt injections and hallucinations won’t be noticed until they have already caused the damage. Moreover, humans are subjected to innate bias which may affect their judgment.
In addition, when LLM-as-a-Judge was compared to using human as judges, the aforementioned methods were proven to have over 80% agreement with each other, resulting in the LLM-as-a-Judge method far better to provide constant oversight into an AI’s behavior.
Overall, both the human as a judge and LLM-as-a-Judge are unideal architectures for AI guardrails. LLM-as-a-Judge, in particular, albeit working in real-time and considerably cheaper than using human as judges, are still extremely costly to make and have a significant decrease in latency as the number of tokens increases.
So, what’s the solution to a cost-friendly, high accuracy, low latency guardrail architecture?
The multiSLM architecture
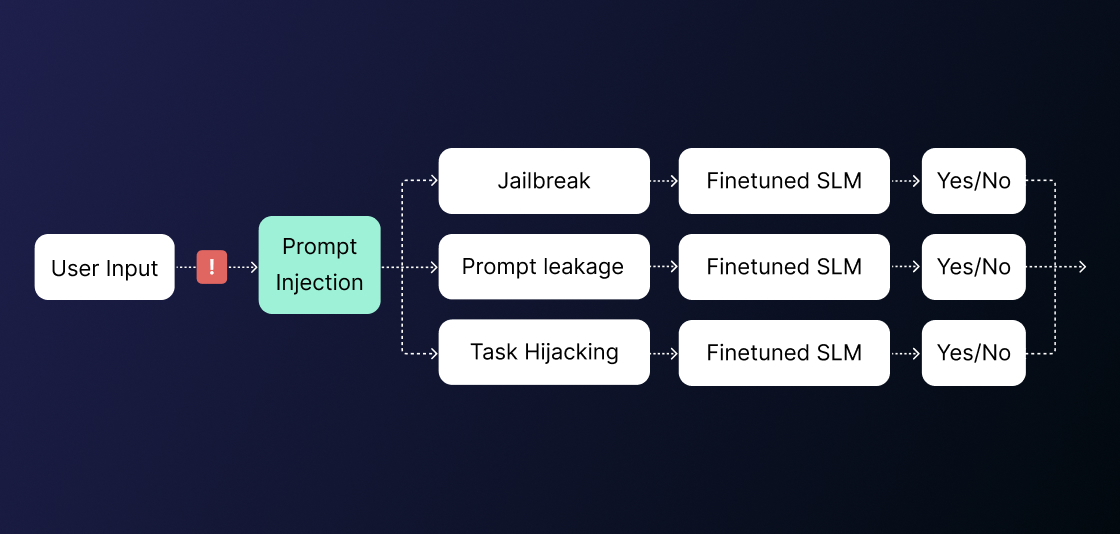
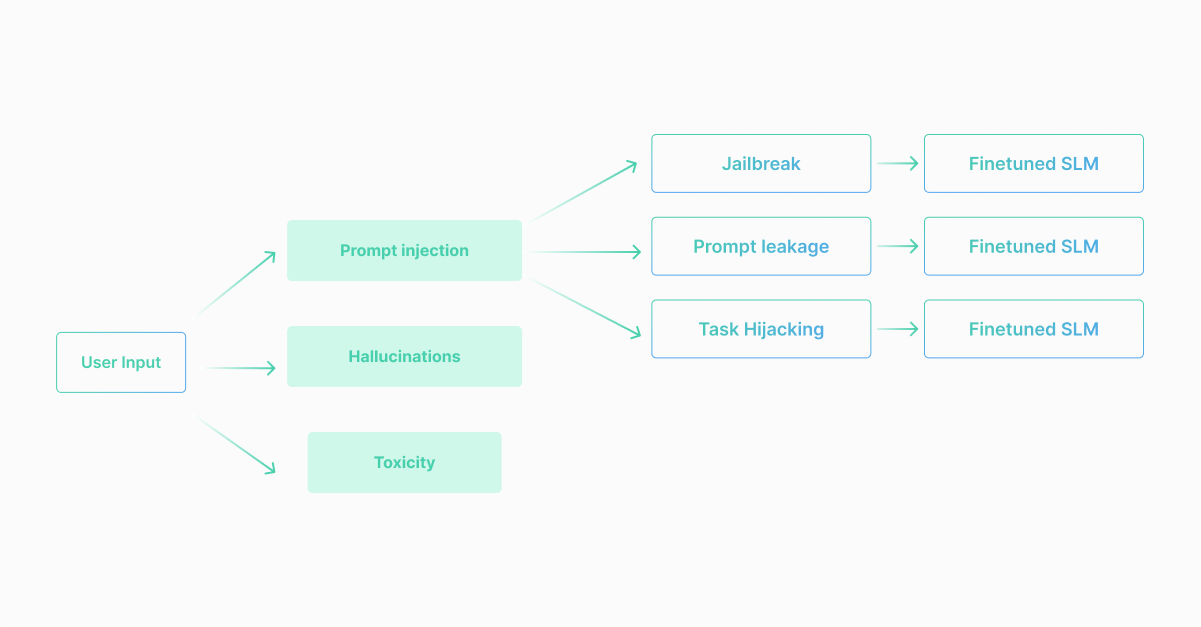
The superior method when choosing your guardrails sits with the multiSLM architecture. This architecture is built with many small language models that are fine-tuned and trained for very specific tasks. Together, the SLMs are able to process queries at very fast, highly accurate rates, and provide exceptional real-time oversight into an AI’s behavior.
Looking at the diagram below, you can see that a user query comes in, and it needs to be checked for prompt injections, hallucinations, and toxicity. Rather than sending that query directly to an LLM, the task is split into 3 small subtasks. These subtasks are then sent to a fine-tuned SLM, which is able to give a response. Each of these subtasks are essentially binary classification tasks, meaning that they give a ‘Yes’ or ‘No’ answer.
Together, these answers provide an answer as to whether the query violates, or adheres to the policies at hand.
Advantages of the multiSLM architecture for guardrails
There are 2 important advantages of this approach for guardrails that make it superior to any other guardrail method out there.
1. It has the fastest latency and TTFT
By splitting each task into smaller subtasks, and fine-tuning each SLMs for a specific purpose, a single message can run through tens of SLMs simultaneously, and receive results in less than a second. Fine-tuned SLMs (and finetuning in general) also allow for smaller prompts, which means there are less input tokens, and a lower TTFT.
Furthermore, smaller models have a lower latency by an order of magnitude. This means that even though we parallelize multiple requests, and could encounter spikes and variations, the latency is still significantly lower when compared to LLMs.
2. It has the highest accuracy
Research of recent years has proven that fine-tuned LLMs (or SLMs) outperform even the most sophisticated LLMs when solving very specific tasks. For example, this study showed that it’s possible to fine-tune a small LLM and achieve a competitive level of performance in hallucination detection when compared to the prompt-based approaches, with the most advanced LLMs such as GPT-4.
Our method of fine-tuning SLMs is the most accurate guardrail architecture, providing the most accuracy and least disagreement over AI applications in detecting safety and reliability issues.
These high accuracy, fast latency guardrails are guaranteed to provide far superior protection of your AI in comparison to the LLM-as-a-judge method.
Aporia’s multiSLM Detection Engine
Aporia has created the first multiSLM Detection Engine guardrails, which can protect any GenAI app in real-time from all security and reliability threats. With the multiSLM architecture being at the core of Aporia’s Guardrails, Aporia is proud to be providing engineers globally with the highest quality of safety and reliability guardrails they can find.
After integrating into an AI app, developers need to simply choose the guardrail policies they want to oversee their AI. After configuring each guardrail, customizing it to their exact liking, they simply need to switch it on to begin the oversight. Should a message be found to violate a policy, it will take the action chosen in the configuration in real-time, such as rephrasing or blocking before it causes real damage.
Prompt injections are blocked before they reach the AI, and hallucinations are rewritten before they reach the end-user. There are many guardrail policies that are available to oversee both the AI and the user messages. Plus, if a policy isn’t there, we also offer the option to create a custom policy from scratch with our pre-built custom policy creator.
In addition to this, Aporia offers a unique dashboard of live messaging updates that appear from both the user and the AI. Should a message violate a policy, it is flagged along with the action that was taken. Furthermore, there are comprehensive dashboards available that analyze your AI and users’ behavior and give analytical summaries with which you can draw many
Aporia’s 2024 Benchmark Report
As they say, the proof is in the pudding. So let’s briefly go over Aporia’s 2024 benchmark report which compares Aporia’s Guardrails to those of Nvidia/NeMo and GPT-4o.
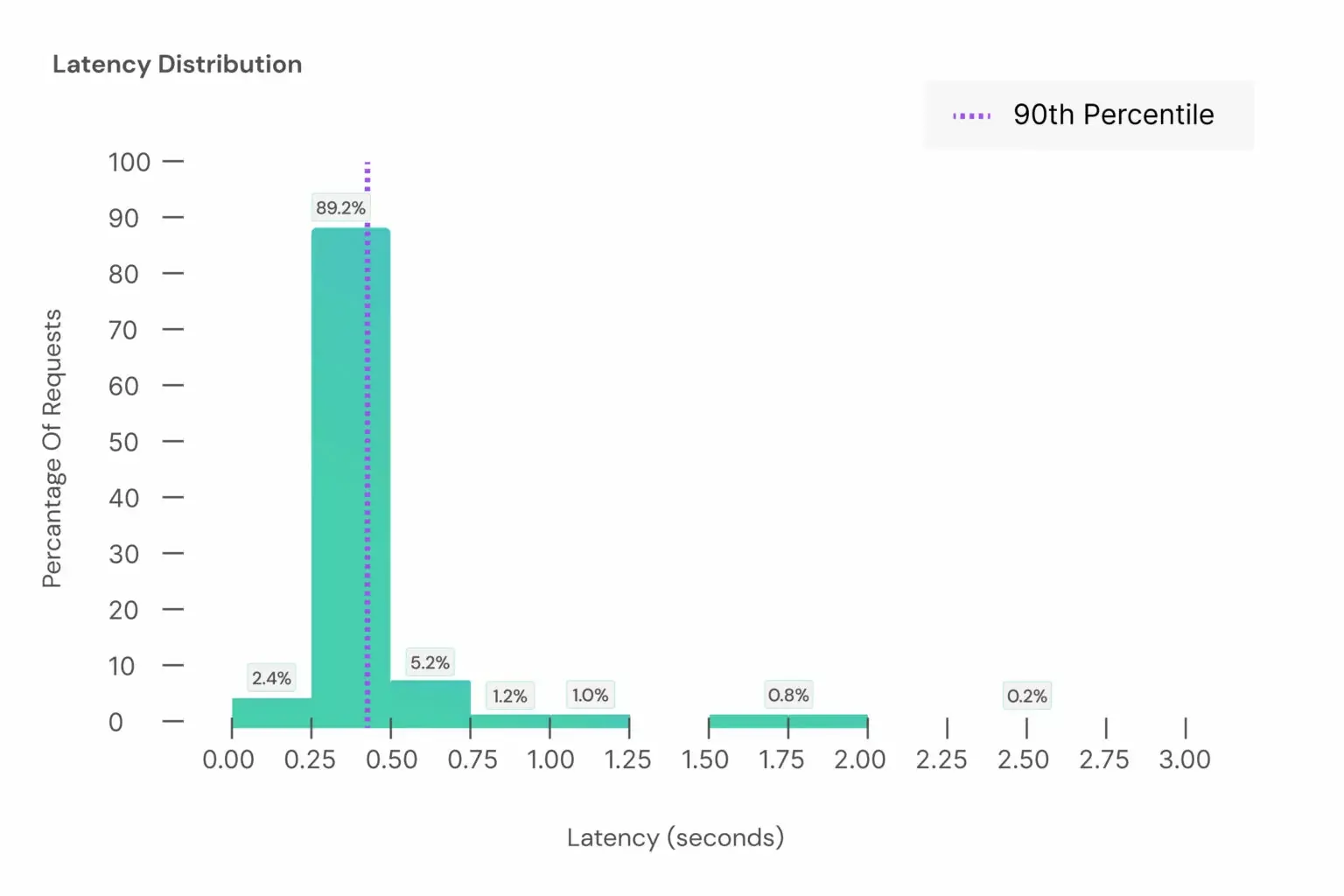
Aporia benchmarks at an average latency of 0.34 seconds and excels with a P90 latency of 0.43 seconds. These scores underscore its efficiency in processing AI interactions with minimal delay.
In addition to this, Aporia is shown to outperform GPT-4o and NeMo Guardrails in the detection accuracy of hallucinations. Mitigating hallucinations is probably one of the toughest challenges engineers face as they strive to get an LLM-based application to production. Unfortunately, hallucinations are an inseparable part of any LLM-based application to date, a part that often prevents said applications from ever reaching the user’s hands.
Aporia offers real-time hallucination mitigation that outperforms GPT-4, NeMo and GPT-3.5
Unmatched security and reliability with Aporia
In addition to hallucinations, there are other significant factors to consider as well. These factors can be divided into two main categories:
Security-related concerns – Including the need to handle PII, data leakage concerns, and prompt injections properly.
Reliability – The different aspects required to ensure the quality of the agent’s response. Such as making sure the agent stays on topic and provides relevant answers, as well as verifying it does not use toxic, biased, or racist language.
Aporia provides highly accurate policies thanks to our SLM Detection engine to help ensure the security and reliability of AI agents:
Precision
Recall
F1-Score
Off topic detection
0.96
0.91
0.94
Toxicity
0.87
0.84
0.86
Prompt Injection
0.95
0.80
0.87
PII – Phone number
0.94
0.91
0.93
PII – Email
1
1
1
PII – Credit number
1
0.93
0.96
PII – IBAN
1
1
1
This benchmark report clearly shows how significant SLMs are and how, when properly fine-tuned and trained, they work to provide the most accurate and fast Guardrails for any AI app.
To summarize
Safeguarding your AI agent is essential. Moreover, the responsibility of providing constant, unbiased oversight to any AI falls on AI guardrails. However, the quality of guardrails varies, as the architecture and structure of the guardrails vary massively. The LLM-as-a-judge architecture is less than ideal when choosing guardrails, as this leads to slow, inaccurate, and biased oversight results.
The superior architecture to look for in any guardrails is a multiSLM architecture, in which many SLMs have been fine-tuned for very specific actions, and work simultaneously to provide sub-second oversight and near-perfect accuracy into AI behavior. This architecture is optimal for ensuring that the oversight is unbiased and accurate, thereby preventing issues such as hallucinations and misinformation.
Aporia’s Guardrails, built on a multiSLM Detection Engine, are the first of its kind to offer AI guardrails with this optimal architecture. They provide AI engineers with the ability to properly secure and safeguard any AI agent, as well as ensure reliability is maintained. This unique architecture is proven to be superior through Aporia’s 2024 benchmark report, in which Aporia’s Guardrails are shown to outperform both those of Nvidia/NeMo and Gpt-4o guardrails.
Maintaining AI safety and reliability is important, as is ensuring your guardrail architecture is the very best. Learn more about Aporia’s mutliSLM Detection Engine and the Guardrails we offer.




 Aporia Team
Aporia Team