

Aporia Has Been Acquired by Coralogix
We have some incredible news to share: Aporia has been acquired by Coralogix. This moment represents the culmination of years...
 Liran Hason
Liran Hason
Read Now
3 min read
Aporia has been acquired by Coralogix, instantly bringing AI security and reliability to thousands of enterprises | Read the announcement
We are incredibly proud to announce our 2024 guardrail benchmarks and multiSLM detection engine. In the realm of AI-driven applications, ensuring low latency and maintaining high accuracy are pivotal for delivering seamless user experiences. Aporia’s Guardrails have undergone rigorous benchmarking to allow us to demonstrate to you their capabilities in real-time response handling.
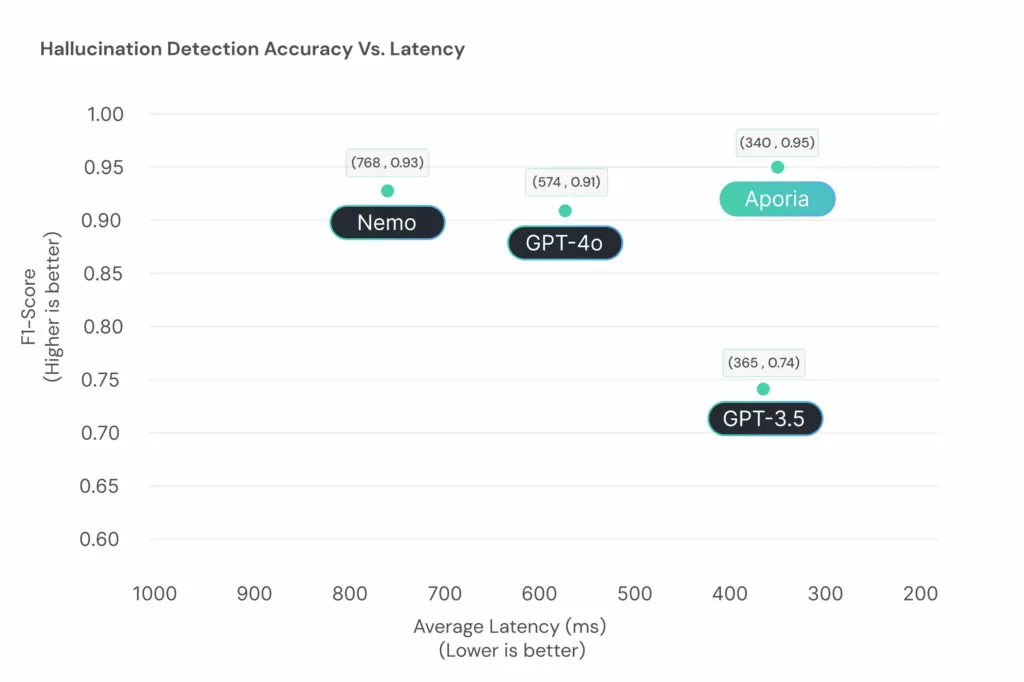
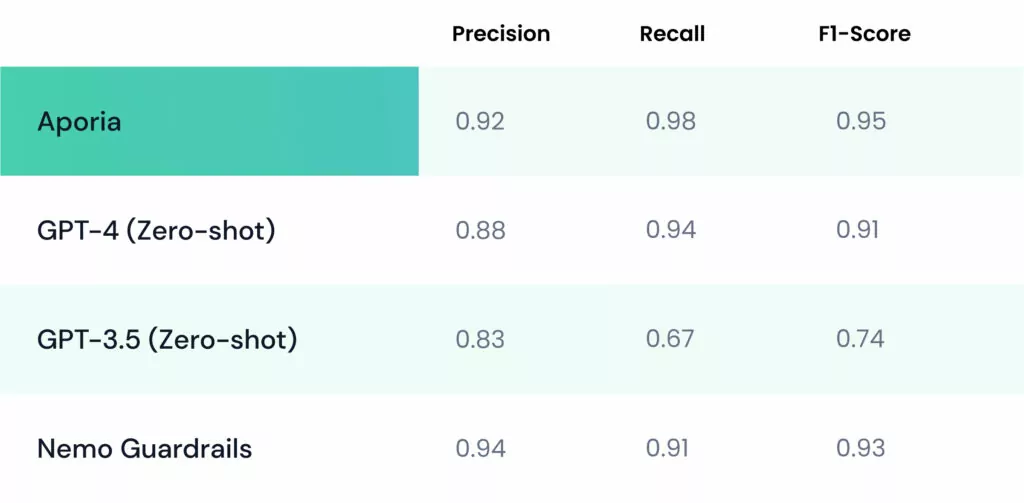
Notably, Aporia achieves an average latency of 0.34 seconds and excels with a 90th percentile latency of 0.43 seconds, underscoring its efficiency in processing AI interactions with minimal delay. In addition, Aporia is shown to outperform GPT-4o and NeMo Guardrails in the detection accuracy of hallucinations. This is achieved through our unique in-house infrastructure, which trains multiple specialized small language models (SLMs).
By distributing our workload across many specifically trained SLMs, rather than relying on a single large language model (LLM), we ensure greater robustness and flexibility in our Guardrails and the policies we offer.
Additionally, we leverage proprietary databases that combine insights from LLM applications, open-source data, and our dedicated AI research. These benchmarks highlight Aporia Guardrails’ commitment to advancing AI deployment standards, providing developers and organizations with a trusted solution for deploying AI applications that are both responsive and secure.
Aporia vs Nvidia/NeMo
Aporia’s multiSLM Detection Engine
Latency
Hallucinations accuracy
Security and reliability
Aporia outperforms NeMo, GPT-4o, and GPT-3.5 in both hallucination detection accuracy and latency.
In order to achieve such a low latency, as well as maintain a high accuracy, we decided to take a decentralized approach and employ multiple SLMs rather than relying on a single LLM. Each SLM is responsible for a different policy, such as hallucinations or prompt injections, enabling us to distribute the workload across multiple models thereby reducing latency and improving response times.
In addition to this, it provides robustness and reliability for the detection engine as any failure issues with one mode will not disrupt the entire system. Moreover, smaller models are easier to debug, facilitating transparency and trust in the AI’s decision-making process.
The use of SLMs over 1 big LLM has allowed us to create lightning-fast and highly accurate Guardrails that set new standards in the industry, and which our users can benefit from to secure their AI from any malicious threats or inaccurate responses.
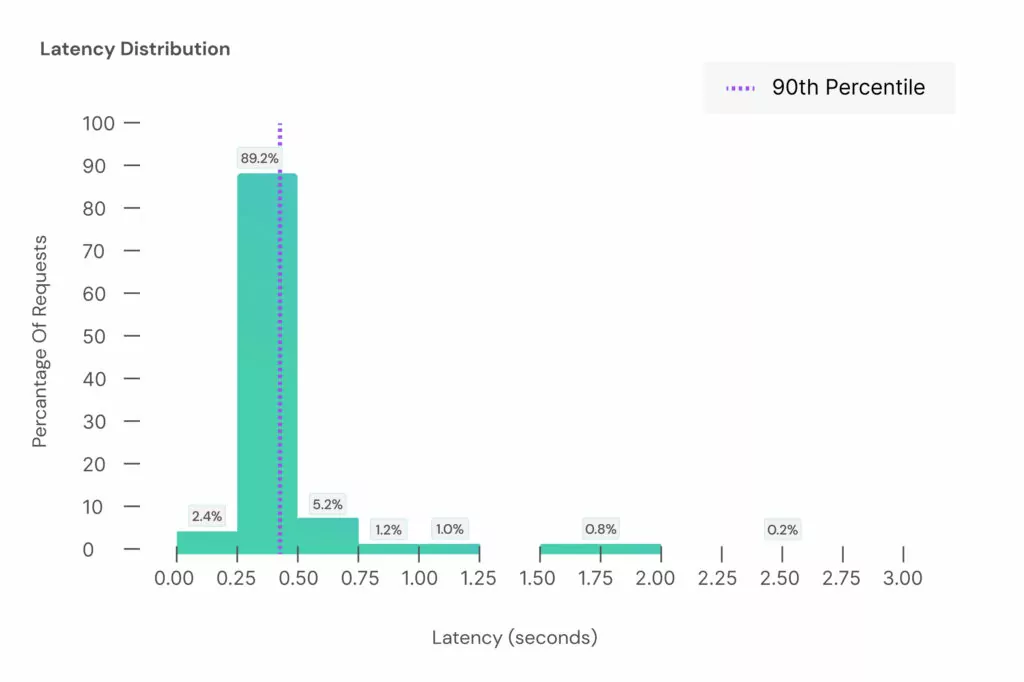
With the introduction of AI conversational agents, latency has become a significant concern for both the business and the user. Users expect immediate replies and human-like interactions, which results in a demand for very low-latency applications from businesses. This has become especially important for voice-based applications. Applying real-time Guardrails on top of this app requires a solution with extremely low latencies to not hinder the application’s performance.
We are proud to announce that Aporia benchmarks at an average latency of 0.34 seconds and a 90th percentile of 0.43 seconds.
Mitigating hallucinations is probably one of the toughest challenges engineers face as they strive to get an LLM-based application to production. Unfortunately, hallucinations are an inseparable part of any LLM-based application to date, a part that often prevents said applications from ever reaching the user’s hands.
Guardrails can offer a solution to mitigate hallucinations by preventing them from ever reaching the end users. Aporia offers real-time hallucination mitigation that outperforms GPT-4, NeMo and GPT-3.5
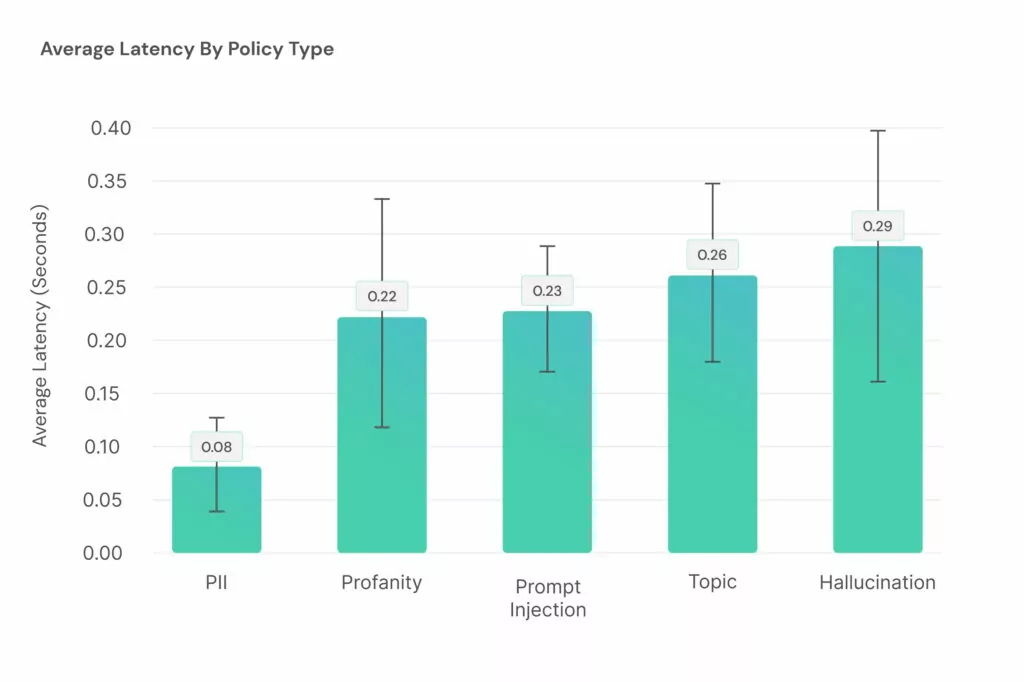
In addition to hallucinations, there are other significant factors to consider as well. These factors can be divided into two main categories:
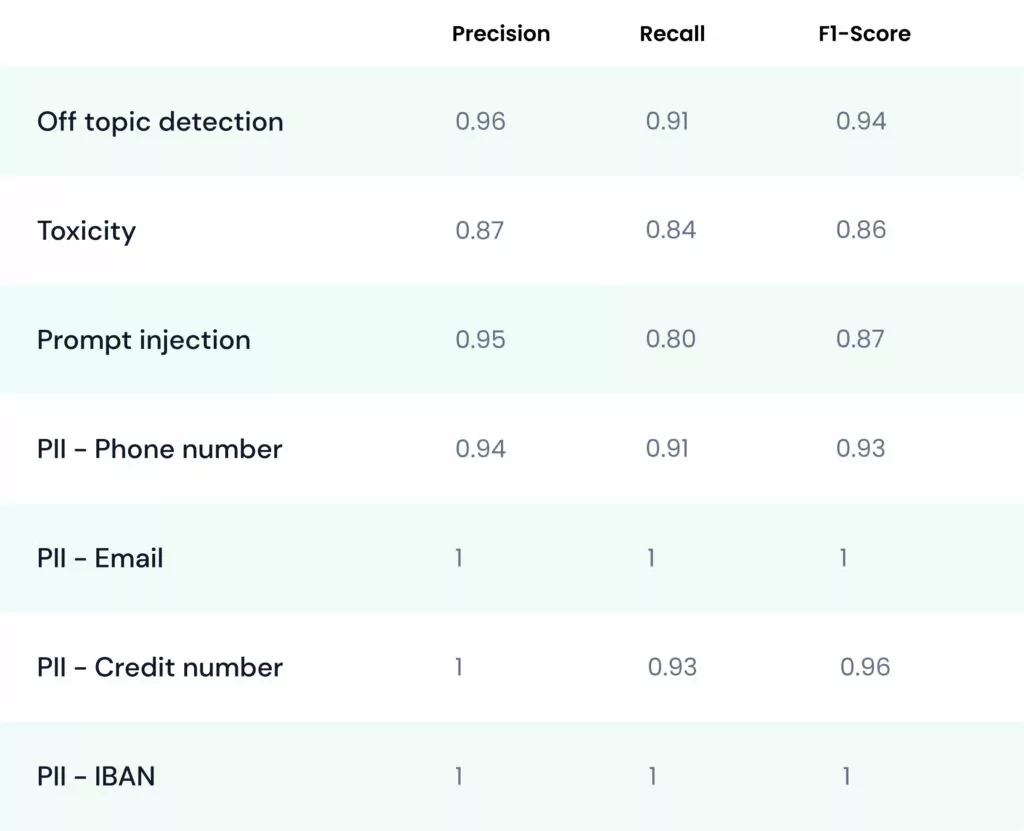
Aporia provides highly accurate policies thanks to our SLM Detection engine to help ensure the security and reliability of AI agents:
In developing robust AI systems, the quality and diversity of datasets play a crucial role in training and evaluation. Here, we present distinct datasets aimed at enhancing the capabilities of language models through rigorous testing and validation.
Together, these datasets serve to advance the field by evaluating AI models’ ability to maintain context fidelity and accurately classify multi-topic interactions.
There are three primary types of LLM hallucinations:
Among these, context contradiction is probably the form with the most significant effect. Therefore, our initial dataset is focused on evaluating a system’s ability to detect context contradictions. We generated this dataset using two pre-existing datasets available on HuggingFace.
To create examples of hallucinations, we used GPT-4o to generate a dataset of random pieces of knowledge across multiple different subjects. We then used GPT-4o to generate a question related to the context, as well as an answer to the question that contradicts the context. We combined all three datasets to a single test set, available here.
Although there are numerous topic classification datasets available, the task of topic detection in a Guardrails system is inherently multi-label. In real-world interactions with an LLM, each sentence can pertain to multiple topics. To create a suitable dataset for this task, we repurposed an existing topic classification dataset (link here). This dataset includes 6 topics.
For each topic, we randomly selected 250 examples and also sampled examples from different topics to serve as distractors. To ensure that these distractors are truly unrelated to the topic in question, we defined a list of closely related topics to avoid sampling. Consequently, we created 6 datasets – one for each topic – each containing 250 correct examples and 250 distractors (The complete set can be found here).
Fortunately, high-quality labeled datasets for the rest of the detectors were already publicly available, so we used the following datasets:
These benchmarks highlight the efficiency and accuracy of our Aporia Guardrails, showcasing our commitment to enhancing AI reliability. While we take pride in these benchmarks, we acknowledge the ongoing need for improvement and are dedicated to setting new standards in AI safety and performance.
At Aporia, we are focused on empowering engineers to deploy safe AI solutions through our Guardrails, bolstered by our sophisticated SLM Detection Engine. Our Guardrails are designed not to compromise app performance or safety but rather to seamlessly integrate, ensuring a smooth user experience without disruptions. We are enthusiastic about advancing Aporia and witnessing the transformative impact of enhanced AI capabilities.
To start utilizing our Guardrails and leverage our multiSLM detection engine, visit aporia.com.
We have some incredible news to share: Aporia has been acquired by Coralogix. This moment represents the culmination of years...
Liran Hason

We are thrilled to announce that Aporia’s Guardrails has been recognized by TIME as one of the 200 Best Inventions...
Liran Hason

We recently announced our availability in the Microsoft Azure Marketplace. This milestone allows Azure customers to access Aporia’s innovative solutions...
 Gadi Bessudo
Gadi Bessudo

We are pleased to announce that Aporia Guardrails are now available on the Google Cloud Marketplace. This partnership makes it...
 Niv Hertz
Niv Hertz

We’re excited to announce our partnership with Portkey, aimed at enhancing the security and reliability of in-production GenAI applications for...
 Sabrina Shoshani
Sabrina Shoshani

In the fast-evolving world of AI, and the latest launch of GPT-4o, businesses are becoming more and more likely to...
Sabrina Shoshani

With all the greatness that AI promises, it remains vulnerable to several risks, including AI hallucinations, prompt attacks, and data...
 Aporia Team
Aporia Team

In the ever-evolving field of AI, the maturity of production applications is a sign of progress. The industry is witnessing...
Aporia Team