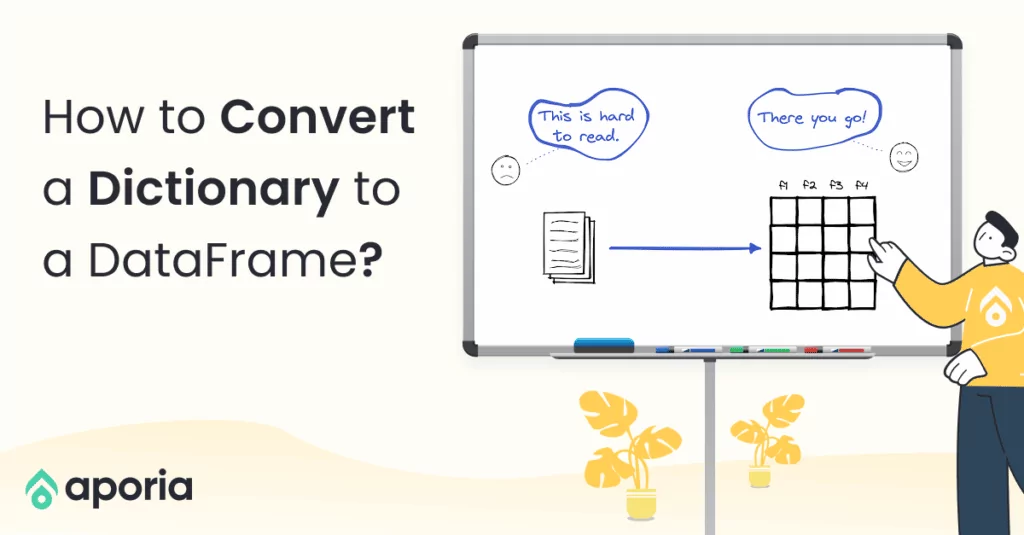
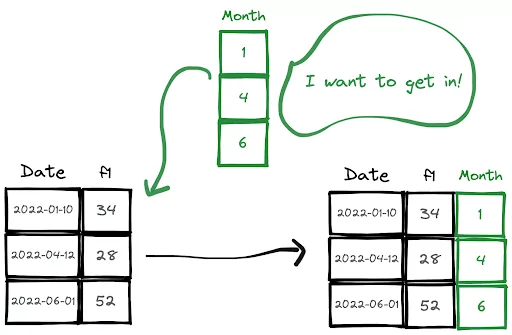
We often need to create a new column as part of a data analysis process or a feature engineering process in machine learning. In this short how-to article, we will learn how to add a new column to an existing Pandas and PySpark DataFrame.
Pandas
months = [1, 2, 6]df["Month"] = months
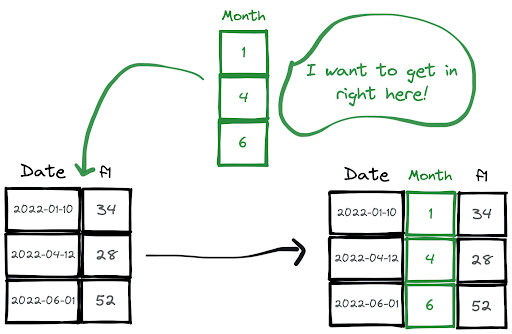
This method adds the new column at the end of the DataFrame as you see in the drawing above. If you want to add the new at a specific location, use the insert function.
months = [1, 4, 6]df.insert(1, "Month", months)
The 3 parameters inside the insert function are the location, name, and the values of the new column. Therefore, the code block above adds a column named “Month” at index 1 which means the second column.
Instead of writing the month values manually, we can extract this information from the date column which is more practical when working with large datasets.
# Add at the enddf["Month"] = df["Date"].dt.month# Insert as the second columndf.insert(1, "Month", df["Date"].dt.month)
PySpark
The new column can be added using the withColumn function. In PySpark, we cannot pass a list as the values of the new column. However, we can extract the month information from the date using the month and col methods.
from pyspark.sql import functions as Fdf = df.withColumn("Month", F.month(F.col("Date")))
This question is also being asked as:
Add a new column in Pandas DataFrame.
How can I add a new computed column in a DataFrame?



 Alon Gubkin
Alon Gubkin