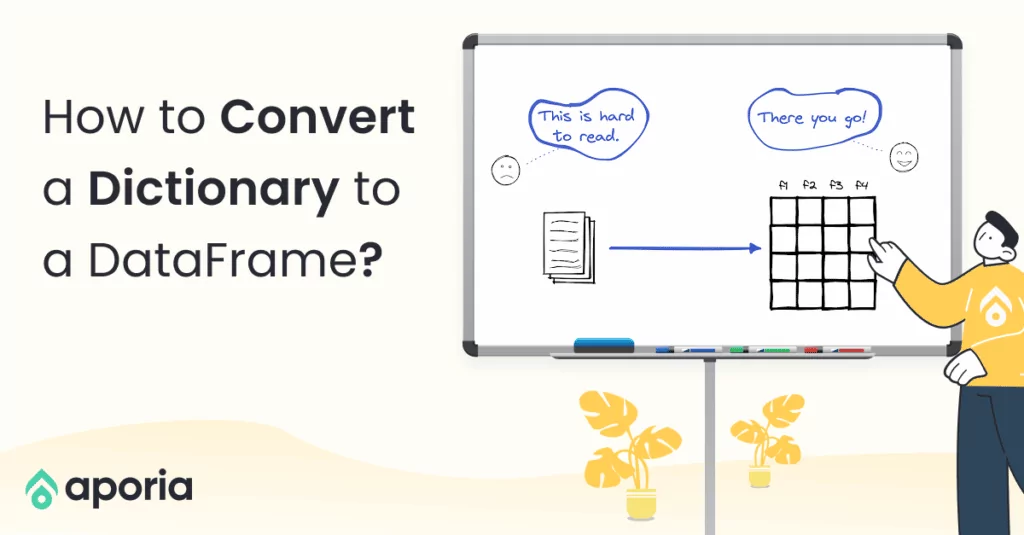
DataFrames are great for data cleaning, analysis, and visualization. However, they cannot be used in storing or transferring data. Once we are done with our analysis, we need to write the DataFrame into a file.
One of the commonly used file formats for this purpose is CSV. In this how-to article, we will learn how to write Pandas and PySpark DataFrames to a CSV file
Pandas
The to_csv function can be used for this task. We just need to specify the file path.
df.to_csv("project-1/results.csv")
If we use the default parameter values, row names (i.e. index) are written in the file so when we read back the csv file into a DataFrame, the index will be shown as a new column. We can change this behavior by setting the index parameter as False.
We also have the option to write only some of the columns, which is useful if there are some redundant columns in the DataFrame. The list of columns to be written is given to the columns parameter.
We can use the csv method provided by the DataFrameWriter class.
df.write.csv("project-1/results")
This line of code creates a folder named results and writes the csv file in it. PySpark writes files in partitions by default. We can have the data written in a single csv file by using the repartition method.
df.repartition(1).write.csv("project-1/results")
Unlike Pandas, PySpark does not write the header (i.e. column names) to the csv file. We can change this behavior by setting the header option as True.


 Alon Gubkin
Alon Gubkin