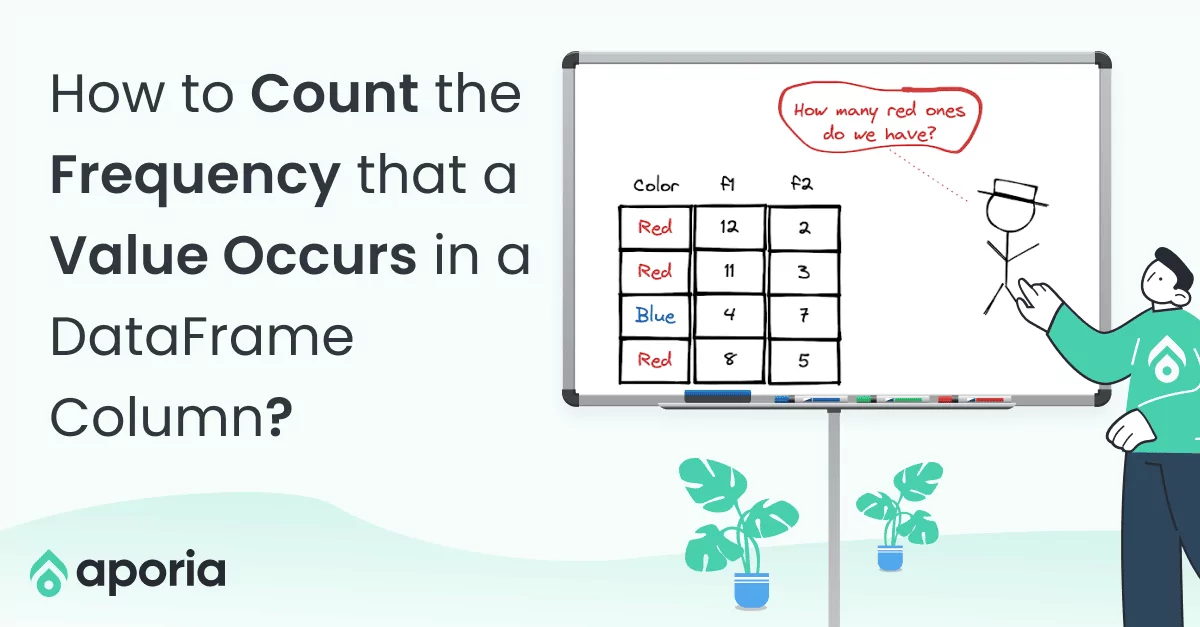
In a column with categorical or distinct values, it is important to know the number of occurrences of each value. In this short how-to article, we will learn how to perform this task in Pandas and PySpark DataFrames.
Pandas
The value_counts function returns the distinct values in a column along with their number of occurrences.
df["Color"].value_counts()
Missing values are ignored by default. If we know that there are missing values in a column, it is best to count them as well. The dropna parameter is set to False to include the missing values.
df["Color"].value_counts(dropna=False)
PySpark
To count the number of occurrences of distinct values in a column, we use the groupby and count functions. The rows are grouped by the column of interest and then the count function is applied.
df.groupby("name").count().show()
The missing values are included in this calculation.
This question is also being asked as:
How can I return the number of times an element appears in a column


 Alon Gubkin
Alon Gubkin