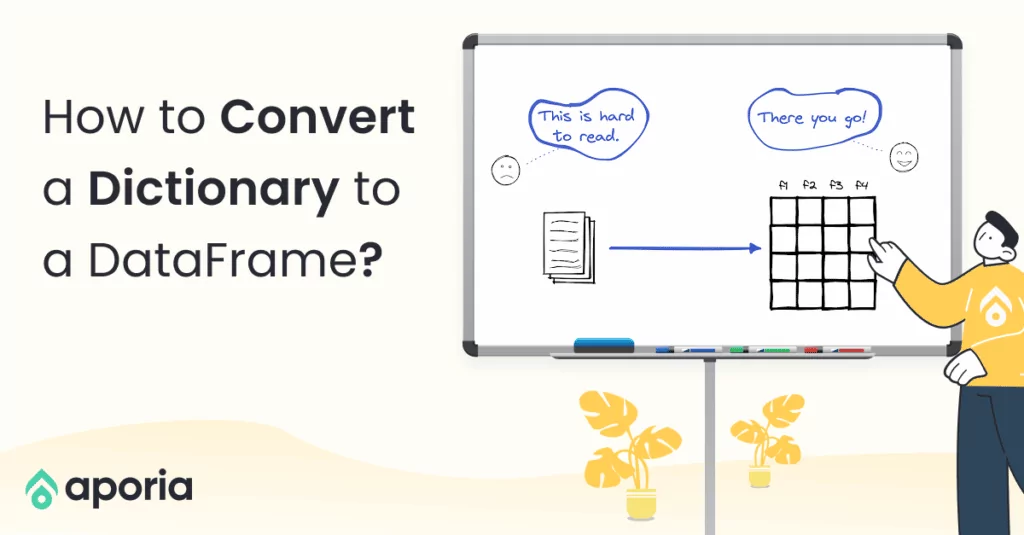
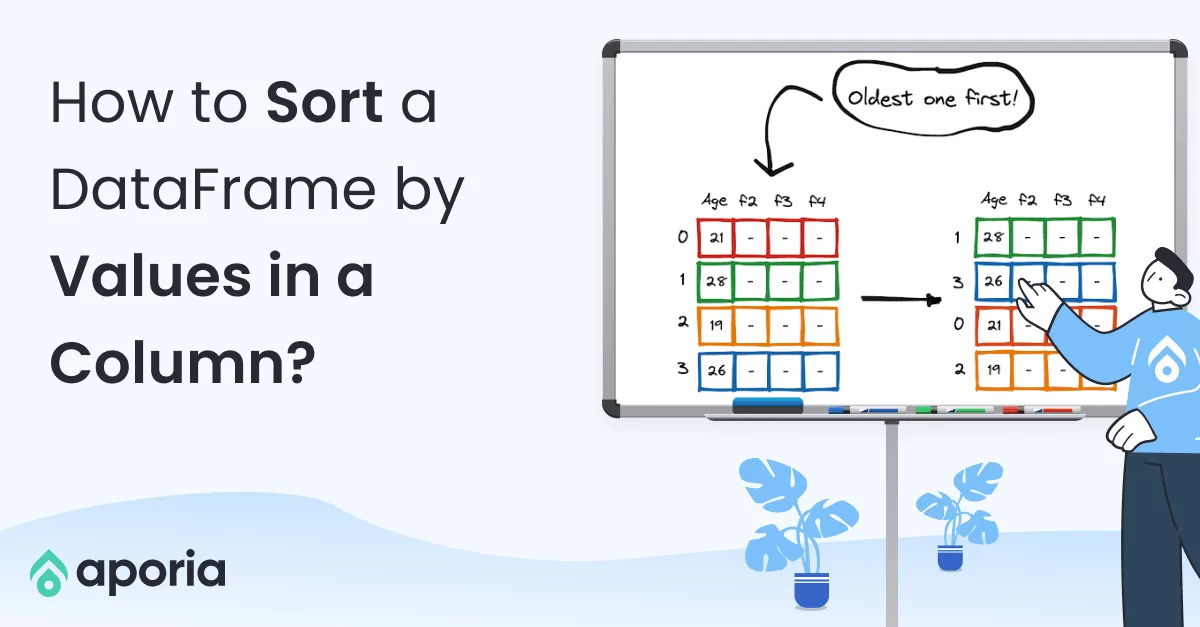
In this short how-to article, we will learn how to sort the rows of a DataFrame by the value in a column in Pandas and PySpark.
Pandas
The sort_values function can be used for this task. We just need to give it the column name.
df.sort_values(by="Age")
By default, the index of the rows prior to sorting are kept, which is not an ideal situation. We can change this behavior by using the ignore_index parameter.
df.sort_values(by="Age", ignore_index=True)
By default, the values are sorted in ascending order and this can be changed using the ascending parameter.


 Alon Gubkin
Alon Gubkin