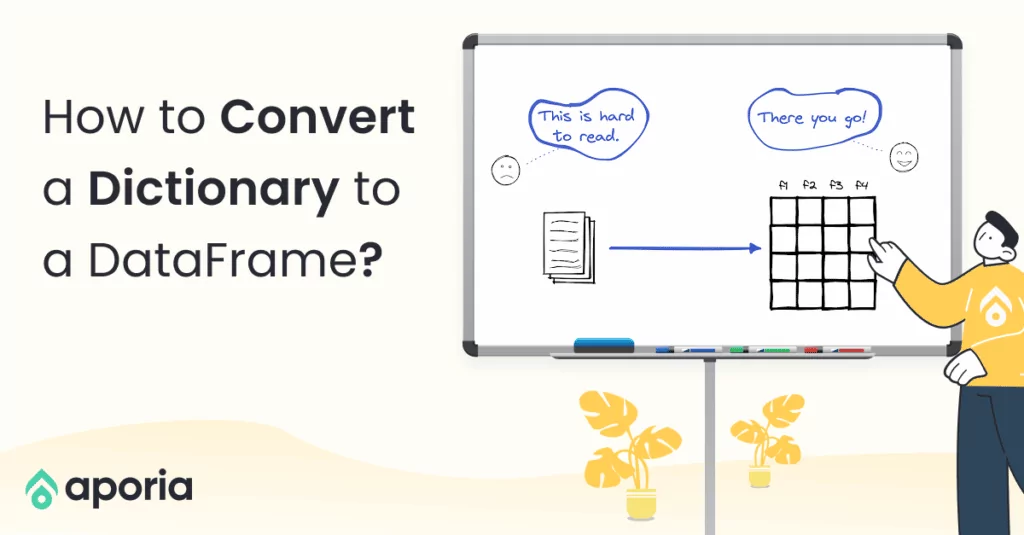
DataFrame is a two-dimensional data structure, which consists of labeled rows and columns. Each row can be considered as a data point or observation, and the columns represent the features or attributes of the data points.
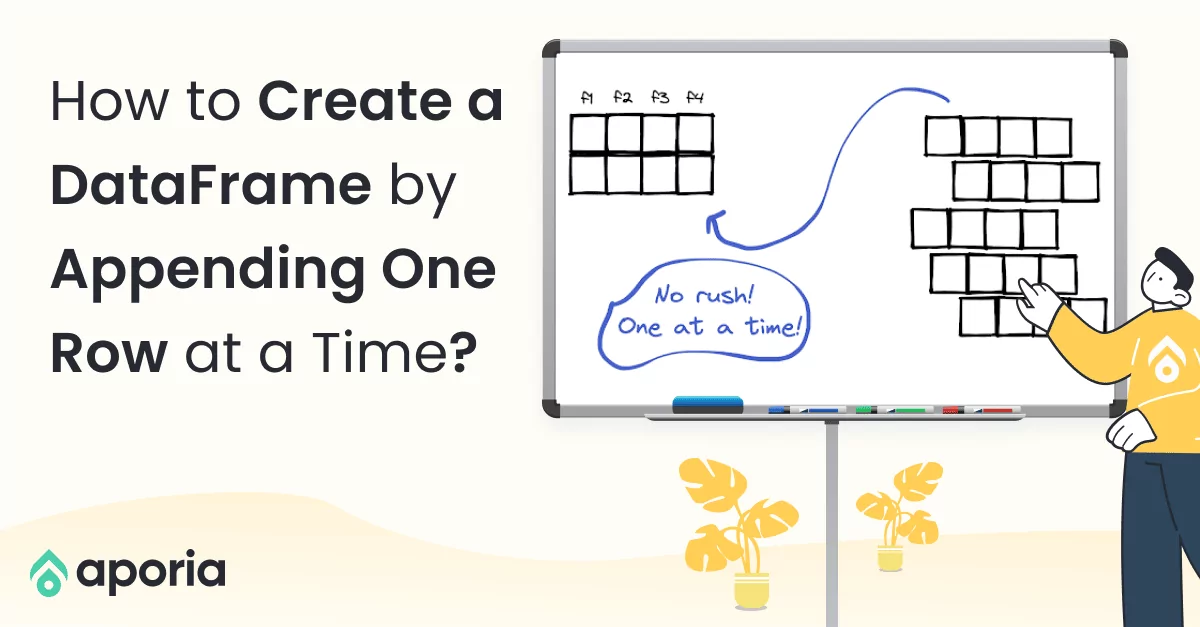
We can create a DataFrame by stacking data points (i.e. appending one row at a time). In this short how-to article, we will learn how to perform this task for Pandas and PySpark DataFrames.
Pandas
We can use the loc method to append rows to a DataFrame. The number of values we provide must match the number of columns in the DataFrame.
Consider we have a list of names and a list of scores. We want to create a DataFrame from the values in these lists. It will be a DataFrame with two columns: Names and Score. The first step is to create an empty DataFrame with two columns. Then, we append rows in a for loop.
The for loop takes the first items in both lists and appends as the first row to the DataFrame, and then the second ones, and so on.
PySpark
We can add new rows to a DataFrame by using the union function, which is also used for combining DataFrames with the same schema. Before a row is appended to the DataFrame, it needs to be converted to a DataFrame. Therefore, this operation is more like appending a DataFrame with one row.


 Alon Gubkin
Alon Gubkin