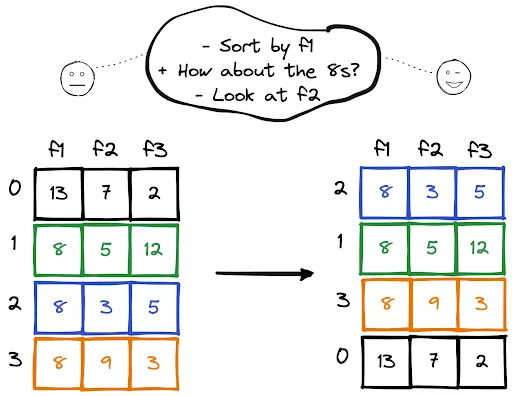
In this short how-to article, we will learn how to sort DataFrame rows by two or more columns. Rows are sorted by the values in the first column. In the case of equality, the values in the second column are checked, and so on.
Pandas
The sort_values function is used for sorting DataFrame rows. To sort by multiple columns, column names are written in a list.
df = df.sort_values(by=["A","B"])
By default, the index of the rows prior to sorting are kept, which is not an ideal situation. We can change this behavior by using the ignore_index parameter.



 Alon Gubkin
Alon Gubkin