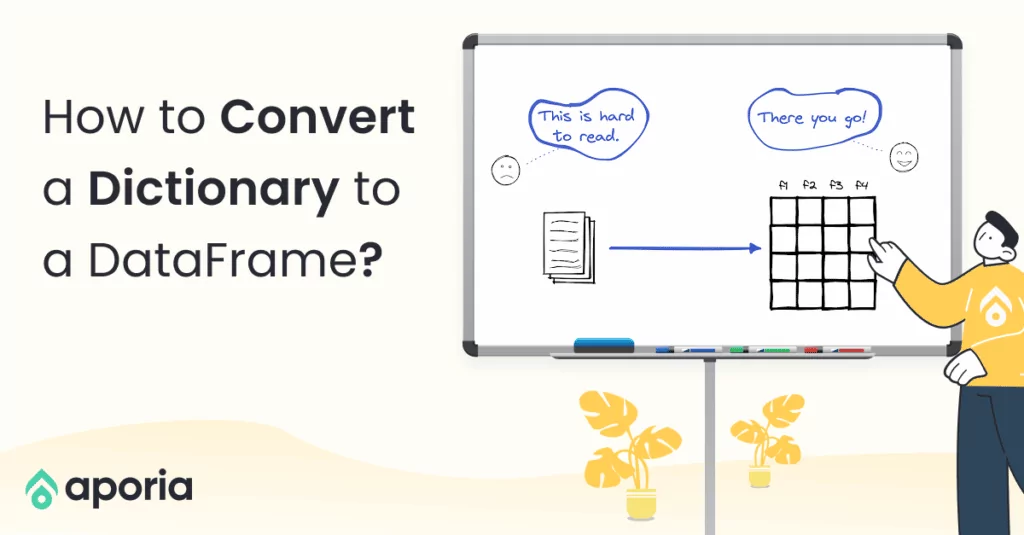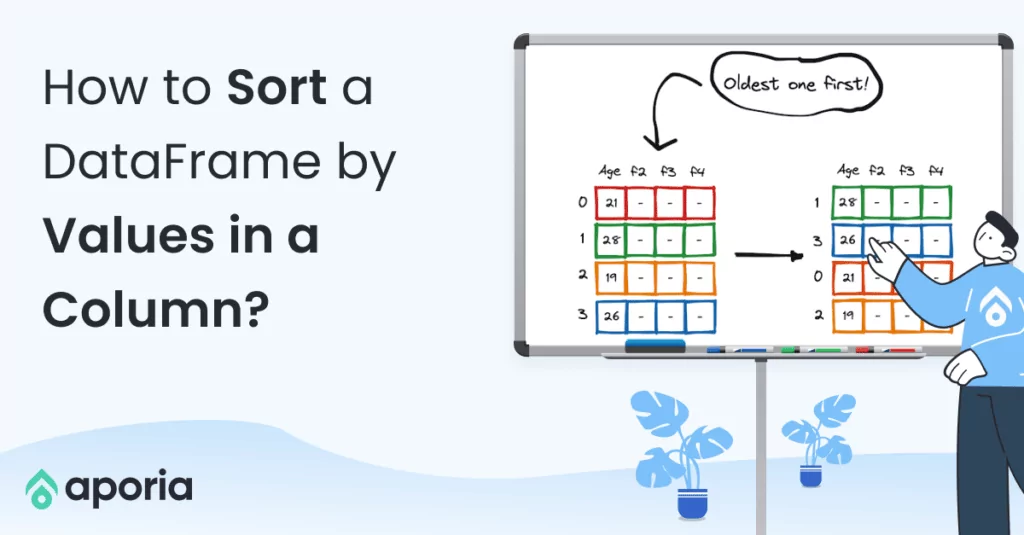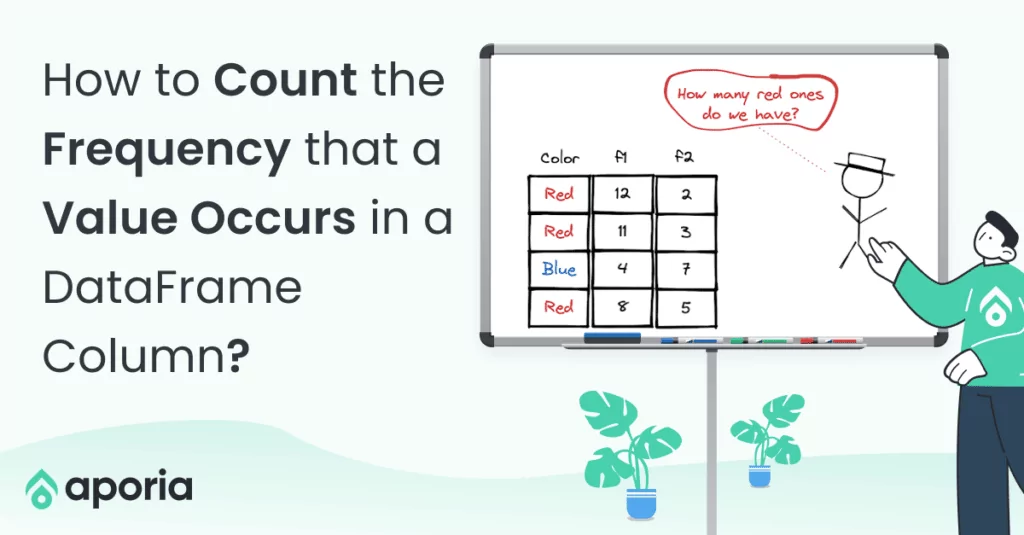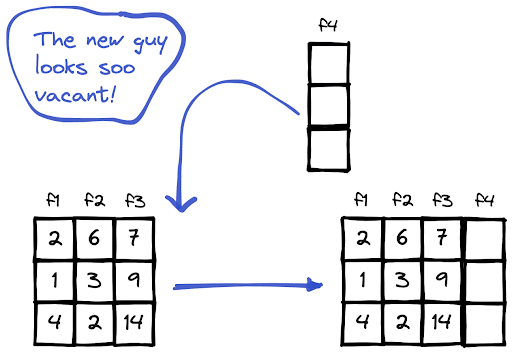

How to Build an End-To-End ML Pipeline With Databricks & Aporia
This tutorial will show you how to build a robust end-to-end ML pipeline with Databricks and Aporia. Here’s what you’ll...
 Alon Gubkin
Alon Gubkin
Read Now
4 min read