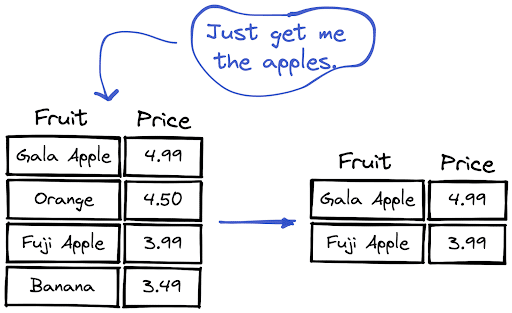
One of the commonly used methods for filtering textual data is looking for a substring. In this how-to article, we will learn how to filter string columns in Pandas and PySpark by using a substring.
Pandas
We can use the contains method, which is available through the str accessor.
df = df[df["Fruit"].str.contains("Apple")]
Letter cases are important because “Apple” and “apple” are not the same strings. If we are not sure of the letter cases, the safe approach is to convert all the letters to uppercase or lowercase before filtering.
PySpark also has a contains method that can be used as follows:
from pyspark.sql import functions as Fdf = df.filter(F.col("Fruit").contains("Apple"))
Letter cases cause strings to be different in PySpark too. We can use the lower or upper function to standardize letter cases before searching for a substring.
from pyspark.sql import functions as Fdf = df.filter(F.lower(F.col("Fruit")).contains("apple"))
This question is also being asked as:
How to filter rows containing a string pattern from a Pandas DataFrame?



 Alon Gubkin
Alon Gubkin