Each column in a DataFrame has a data type (dtype). Some functions and methods expect columns in a specific data type, and therefore it is a common operation to convert the data type of columns. In this short how-to article, we will learn how to change the data type of a column in Pandas and PySpark DataFrames.
Pandas
In a Pandas DataFrame, we can check the data types of columns with the dtypes method.
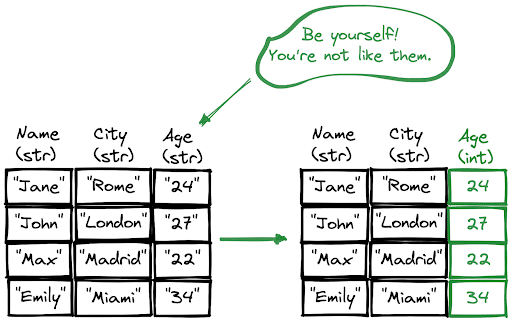
The astype function changes the data type of columns. Consider we have a column with numerical values but its data type is string. This is a serious issue because we cannot perform any numerical analysis on textual data.
df["Age"] = df["Age"].astype("int")
We just need to write the desired data type inside the astype function. Let’s confirm the changes by checking the data types again.
It is possible to change the data type of multiple columns in a single operation. The columns and their data types are written as key-value pairs in a dictionary.
df = df.astype({"Age": "int", "Score": "int"})
PySpark
In PySpark, we can use the cast method to change the data type.
from pyspark.sql.types import IntegerTypefrom pyspark.sql import functions as F# first methoddf = df.withColumn("Age", df.age.cast("int"))# second methoddf = df.withColumn("Age", df.age.cast(IntegerType()))# third methoddf = df.withColumn("Age", F.col("Age").cast(IntegerType()))
To change the data type of multiple columns, we can combine operations by chaining them.



 Alon Gubkin
Alon Gubkin