Selecting rows based on a condition is a common operation in data wrangling. In this short how-to article, we will learn how to use a list of values to select rows from Pandas and PySpark DataFrames.
Pandas
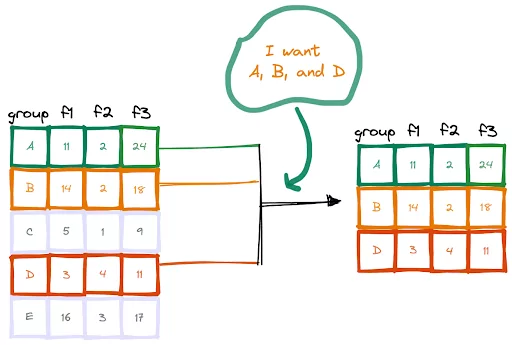
The isin method of Pandas can be used for selecting rows based on a list of conditions. We just need to write the conditions inside a Python list.
df = df[df.group.isin(["A","B","D"])]
If you are interested in selecting rows that are not in this list, you can either add a tilde (~) operator at the beginning or set the condition as False.
PySpark has an isin method which works similar to that of Pandas.
df = df.filter(df.group.isin(["A","B","D"]))
Letter cases cause strings to be different in PySpark too. We can use the lower or upper function to standardize letter cases before searching for a substring.



 Alon Gubkin
Alon Gubkin