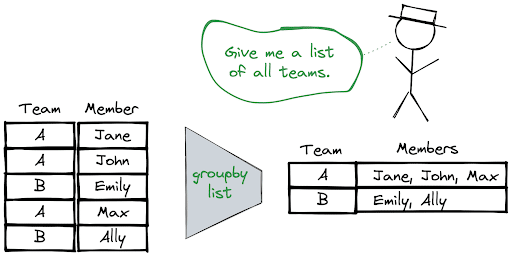
In this short how-to article, we will learn how to group DataFrame rows into a list in Pandas and PySpark. Groups will be based on the distinct values in a column. The values will be taken from another column and combined into a list.
Pandas
The rows are grouped using the groupby function and then we will apply the list constructor to the column that contains the values. We can perform this task as follows:
Members = df.groupby("Team", as_index=False).agg(Members = ("Member", list))
PySpark
To do this operation in PySpark, we can use the collect_list function along with the groupby.
from pyspark.sql import functions as FMembers = df.groupby("Team").agg(F.collect_list("Member"))



 Alon Gubkin
Alon Gubkin