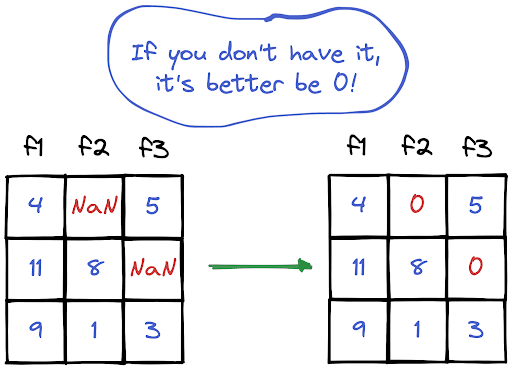
NaN values are also called missing values and simply indicate the data we do not have. We do not like to have missing values in a dataset but it’s inevitable to have them in some cases. Therefore, we need to learn how to handle them properly.
There are different ways of handling missing values. In this how-to article, we will learn how to replace NaN values by zeros in Pandas and PySpark DataFrames.
Pandas
The fillna function can be used for replacing missing values. We just need to write the value to be used as the replacement inside the function.
# Replace all missing values in the DataFramedf = df.fillna(0)# Replace missing values in a specific columndf["f2"] = df["f2"].fillna(0)
PySpark
We can either use fillna or na.fill function. They are aliases and return the same results.
# Replace all missing values in the DataFramedf = df.na.fill(0)# Replace missing values in a specific columndf = df.na.fill(0, subset=["f2"])
This question is also being asked as:
How to replace NaN values in Python?
How to replace NaN value with some other value in Pandas?



 Alon Gubkin
Alon Gubkin