
Concept Drift in Machine Learning 101
As machine learning models become more and more popular solutions for automation and prediction tasks, many tech companies and data...
Aporia has been acquired by Coralogix, instantly bringing AI security and reliability to thousands of enterprises | Read the announcement
Concept Drift is a situation in which the statistical properties of a target variable (what the model is trying to predict) changes over time in unforeseen ways.
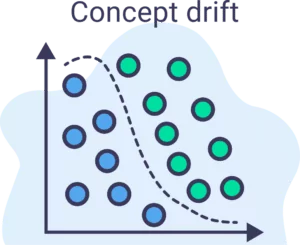
Visually, we can say that a concept is a way to separate between the blue and green dots in the plot above. The black line represents a concept that separates the blue and green dots.
Types of Drifts in Machine Learning
For the following definitions let’s denote the following parameters:
X- Model’s input population.
ŷ – Model’s prediction.
Y- True label population.
Concept drift: a change in the distribution of p(Y |X), meaning that there was a change in the relationship between the input of the model and the true label.
Prediction drift: a change in the distribution of the predicted label – p(ŷ |X), meaning that there was a change in the relationship between the input of the model and the model’s prediction.
Label drift: a change in the probability of a label p(Y).
Feature drift: a change in the probability of p(X), meaning there was a change in the distribution of the model’s input.
In order to better understand the effects of concept drift, we need to distinguish between two types of concept drift:
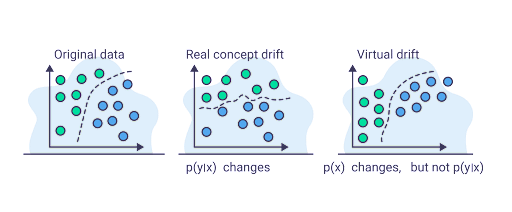
Virtual drift: when p(X) changes but p(Y|X)does not change. Meaning that there was a change in the features’ underlying distribution, but the model’s performance hasn’t changed.
Real drift: There was a change in p(Y|X), meaning the performance of the model changed.
Virtual drift vs real drift is illustrated in the following figure.
Learn more about concept drift here:


As machine learning models become more and more popular solutions for automation and prediction tasks, many tech companies and data...

There is a wide range of techniques that can be applied for detecting concept drift. Becoming familiar with these detection...

What Is Data Drift? Machine learning models are only as good as the data they ingest during and after training....
