

April 7, 2024 - last updated
GenAI For Practitioners
How to build a RAG chatbot from scratch with minimum AI Hallucinations
Intro
At the recent AI Summit in New York, I led a workshop on building Retrieval-Augmented Generation (RAG) chatbots, which received great feedback. Motivated by this, I’ve put together a step-by-step guide to help AI leaders and practitioners create their own RAG chatbot with minimal hallucinations.
What is retrieval-augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is an advanced AI framework and technique in natural language processing that combines elements of both retrieval-based and generation-based approaches. It aims to enhance the quality and relevance of generated text by incorporating information retrieved from a knowledge base. This method gained attention in 2020 with the publication of the research paper, Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
Why use RAG?
RAG is like a ChatGPT on your data! In the context of chatbots, RAG is particularly valuable when applied to datasets containing extensive enterprise documents such as knowledge bases, insurance underwriting documents, product documentation, invoices, contracts, and more. The primary idea is to leverage RAG to create intelligent chatbots, such as the ones built on platforms like LangChain, which can perform question-and-answer tasks over various websites or documents.
The benefits of RAG and myth busted
The benefits of using retrieval-augmented generation for chatbots are notable. It allows chatbots to efficiently and effectively provide responses. Integrating retrieved information into the response generation process, ensures that the chatbot relies on factual data from the retrieval source, minimizing the likelihood of generating false or misleading answers.
In this guide, I emphasize that RAGs (Retrieval-Augmented Generative models) are not a solution for hallucinations, contrary to some marketing blogs’ claims. RAGs essentially enhance Large Language Models (LLMs) by incorporating user-specific data. However, this enrichment doesn’t eliminate the occurrence of hallucinations; rather, it extends them to manifest within the user’s own dataset. In simpler terms, despite the touted benefits of RAGs, they don’t completely eradicate the issue of generating misleading or incorrect information, especially when relying on personalized data. This perspective encourages a more nuanced understanding of the limitations associated with the use of RAGs in managing hallucinations within generative models.
Basic Architecture of RAG Chatbots
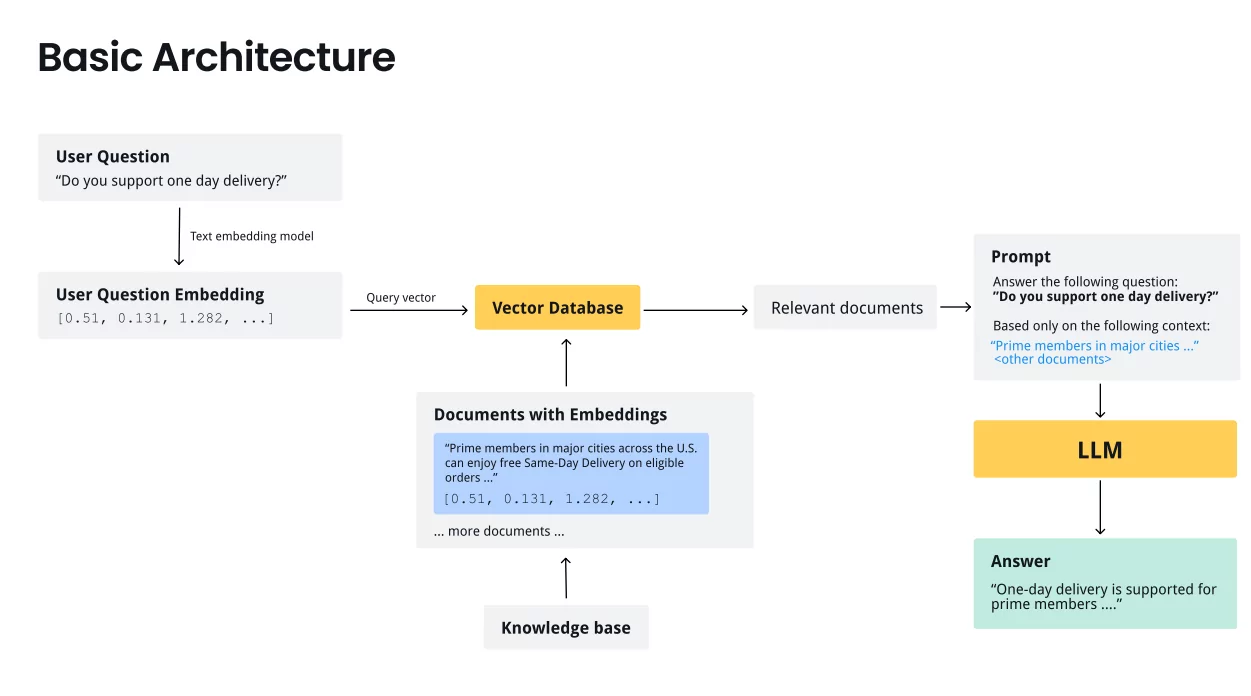
RAG (Retrieval-Augmented Generation) chatbots are designed to provide responses to user queries by combining semantic search and natural language generation techniques. The architecture of RAG chatbots involves several key components:
1. User query processing
When a user poses a question, the query is processed to convert it into an embedding vector. This involves transforming the natural language input into a numerical representation that captures the semantic meaning of the query.
2. Knowledge base
RAG chatbots rely on a knowledge base that contains chunks of text. These chunks are preprocessed and converted into embedding vectors. Each chunk represents a piece of information that the chatbot can use to generate responses.
3. Semantic search
The heart of RAG chatbot architecture lies in semantic search. The system employs methods like cosine similarity to measure the similarity between the user’s query vector and the vectors of text chunks in the knowledge base. The goal is to identify text chunks that are semantically close to the user’s query.
4. Context identification
The text chunks identified through semantic search serve as context for generating responses. By selecting relevant chunks that align with the user’s query, the chatbot ensures that the generated answers are contextually appropriate.
5. Natural Language Generation (NLG)
Once the context is established, the NLG component comes into play. This part of the architecture is responsible for converting the identified context into a coherent and natural language response. It may generate human-like answers using various techniques, including rule-based systems or machine-learning models.
6. Answer presentation
The final step involves presenting the generated response to the user. The chatbot selects the most appropriate answer based on the context identified in the knowledge base and presents it in a way that is easily understandable to the user.
This architecture allows RAG chatbots to handle a wide range of user queries by leveraging the rich information stored in the knowledge base.
Follow-Up question RAG chatbot architecture

The new question asked in the conversation represents a follow-up query, and the architecture of the RAG chatbot is adapted to handle this seamlessly. The process involves using a Language Model (LLM) to isolate the relevant question considering the conversation history. Here’s an elaboration on the continued architecture of the RAG Chatbot for follow-up questions:
1. User follow-up query
The user adds a follow-up question to the existing conversation, seeking information about one-day delivery if they are not a prime member. This continuation of the conversation requires the chatbot to understand the context and provide a relevant response.
2. Language model (LLM) integration
The chatbot employs a Language Model to analyze the conversation history and isolate the new question. The LLM is responsible for identifying the key components of the user’s query and framing it as a standalone question.
3. Standalone question formation
The isolated question becomes a standalone query, detached from the conversation history but still considering the context provided by the user’s previous statements. This standalone question serves as the input for the subsequent steps in the chatbot’s architecture.
4. Normal process – Semantic search and NLG
The standalone question undergoes the normal RAG chatbot process. The question is converted into an embedding vector, and a semantic search is conducted within the knowledge base to identify relevant information. The system selects text chunks that closely match the context of the question, utilizing measures like cosine similarity.
The identified context is then fed into the Natural Language Generation (NLG) component. The NLG generates a coherent response tailored to the user’s query, considering both the original question about one-day delivery and the follow-up inquiry regarding prime membership.
5. Response to the user
The generated response is presented to the user, addressing their follow-up question in a manner that reflects an understanding of the context. The chatbot strives to provide a comprehensive and informative answer to ensure user satisfaction.
Langchain and Vector DB for prototyping RAG systems
Langchain
Langchain is a framework designed for prototyping with a broad spectrum of Language Model (LLM) applications, not limited to just RAGs (Retrieval-Augmented Generative Systems). One of its highlighted features is its ability to chain multiple tools and components together. The framework is implemented in Python and TypeScript.
Vector DB
The code snippets provided below are related to Vector DB also, a component within the broader system. The ‘docs’ variable likely holds a collection of documents, and the ‘vectorstore’ module is used to create a Chroma vector from these documents. The vector is created using the ‘OpenAIEmbeddings()’ method as an embedding. Subsequently, a retriever is created from the vector store.
# Assuming docs is a collection of documents
docs = [...]
# Creating a Chroma vector from the documents using OpenAIEmbeddings
vectorstore= Chroma.from_documents(
documents=docs,
embedding=OpenAIEmbeddings()
)
# Creating a retriever from the vectorstore
retriever = vectorstore.as_retriever()Documents are embedded using OpenAIEmbeddings, and a retriever is created from the vector store.
# Defining inputs to the LLM app using RunnableMap
_inputs = RunnableMap({
"question": lambda x: x["question"],
"chat_history": lambda x: _format_chat_history(x["chat_history"]),
"context": _search_query | retriever |_combine_documents,
})Here, a RunnableMap named ‘_inputs’ is created, which defines how the inputs for the Language Model (LLM) app should be formatted. It includes elements like the question, formatted chat history, and context retrieved from the vector database.
# Constructing the final chain for processing
chain = _inputs | ANSWER PROMPT | ChatOpenAI() | StrOutputParser()The final ‘chain’ is constructed by chaining together different components using the pipe operator. The input, answer prompt, ChatOpenAI component, and StrOutputParser are combined to form the complete processing chain.
Therefore, Langchain seems to be a versatile framework for prototyping various LLM applications, and Vector DB is used within this framework to handle document embeddings and retrieval. The above code snippets illustrate the process of creating vectors from documents, setting up a retriever, and defining the input processing chain for the LLM app within the Langchain framework.
LlamaIndex and Vector DB for prototyping RAG systems
LlamaIndex is a specialized framework explicitly designed for Retrieval-Augmented Generative (RAG) systems. It excels in optimizing the indexing and retrieval of data, tailoring its functionality specifically for RAG applications. Unlike Langchain, LlamaIndex is less general-purpose and is particularly well-suited for tasks related to RAG systems.

The implementation of LlamaIndex involves the use of both Python and TypeScript, showcasing its versatility and compatibility with different programming languages.
# Assuming 'docs' is a collection of documents
vectorstore = VectorStoreIndex.from_documents(docs, ...)This step involves initializing the vector store with the provided documents, forming the basis for subsequent indexing and retrieval operations. VectorStoreIndex is created using the from_documents method, where ‘docs’ represents the collection of documents.
# Create a 'tool' from the vector DB
query_engine_tool = QueryEngineTool(
query_engine=vectorstore.as_query_engine(),
metadata=ToolMetadata(
name="query_engine",
description="Useful if you want to answer questions about XYZ",
)
)Here, a ‘tool’ is generated from the Vector DB using the QueryEngineTool. The tool incorporates the query engine derived from the vector store, enabling efficient querying and information retrieval. Metadata, such as the name and description, is associated with the tool for organizational and descriptive purposes.
# Create an agent from the tool
agent = OpenAIAgent.from_tools([query_engine_tool], verbose=True)
agent.chat("Do you support one-day delivery?")Finally, an agent is instantiated using the tools created, where the OpenAIAgent.from_tools method is employed. The agent is equipped with the previously generated ‘query_engine_tool,’ and a chat interaction is initiated with a user prompt.
Therefore, LlamaIndex stands out as a specialized tool optimized for RAG systems, with a focus on efficient data indexing and retrieval. The provided code snippets illustrate the process of setting up a Vector DB, creating a tool with a query engine, and generating an agent for engaging in conversational interactions based on the established tools.
Chat UI on top of your LLM app
Integrating a Chat User Interface (UI) on top of your Language Model (LLM) application offers a user-friendly and interactive way for users to interact with the underlying language processing capabilities. This approach not only enhances the user experience but also facilitates rapid prototyping and experimentation. Below are key considerations and strategies for implementing a Chat UI on top of your LLM app:
(i) Chainlit Integration for Prototyping
For quick prototyping, consider leveraging Chainlit, an open-source tool that enables the seamless integration of chat functionalities on top of your existing Langchain or Llamalndex app. Chainlit provides a plug-and-play solution, making it easier to visualize and test your LLM capabilities in a conversational setting.

(ii) Custom UI Elements for Specific Use-Cases
Tailor the Chat UI to your specific use-case by incorporating custom UI elements. This ensures that the chat interactions align with the unique requirements of your application. Customization might include specific buttons, forms, or widgets that allow users to interact more intuitively with the LLM, creating a personalized and efficient user experience.
(iii) Internal App Development with Slack/Microsoft Teams Integration
For internal applications, consider developing a Slack or Microsoft Teams chatbot that integrates with your LLM. These popular collaboration platforms offer seamless integration capabilities, allowing users to interact with the LLM directly within the communication channels they already use. This approach can accelerate user adoption within an organization.
Challenge: Retrieval is hard
The challenge of retrieval being hard in the context of RAG chatbots highlights a fundamental issue in assuming that text chunks close in embedding space contain the correct answers. This challenge can lead to inaccuracies, where the chatbot generates responses that might not accurately address the user’s query. The following points elaborate on the challenges associated with retrieval in RAG systems:
1. Semantic Gap
The core problem arises from the assumption that proximity in embedding space directly corresponds to semantic similarity. However, semantic understanding is a complex task, and embeddings may not always capture the degree of meaning. For instance, the question “How can I analyze large datasets?” and the answer “Use Snowflake for efficient large-scale data processing with its cloud-based data warehousing” may have a high distance in embedding space despite being a suitable match.

2. Inadequate Semantic Search
Semantic search, which aims to find documents with similar meaning, faces challenges when dealing with diverse and nuanced language. The distance between embedding vectors is not always indicative of the semantic relationship between a question and its potential answer. In cases where the meaning is context-dependent or relies on domain-specific knowledge, the retrieval process may fail to identify relevant information.

3. Lack of Contextual Understanding
The challenge extends to the difficulty in capturing context. Just because two text chunks are close in embedding space doesn’t guarantee that they form a meaningful question-and-answer pair. The RAG system may struggle to grasp the intricacies of context, leading to responses that may seem relevant based on proximity in embedding space but lack a coherent understanding of the user’s intent.
4. Ambiguity and Vagueness
Natural language is inherently ambiguous and vague. Questions or answers that share similar wording may not necessarily convey the same meaning. The challenge lies in distinguishing between different contexts and interpretations, making it challenging for the RAG system to accurately retrieve and present relevant information.
5. Over-reliance on Embeddings
Relying solely on embedding distances for retrieval overlooks the complexity of language semantics. A more in-depth understanding of language semantics may require advanced techniques that go beyond vector representations. Overemphasis on embeddings without considering the broader context can contribute to the challenges of accurate retrieval.

Addressing these challenges in retrieval is crucial for enhancing the overall performance and reliability of RAG chatbots. It involves exploring advanced techniques in semantic search, context-aware embeddings, and improved natural language understanding to minimize inaccuracies and provide more contextually relevant responses.
Fine-tuning embeddings for improved retrieval
To address the challenge of retrieval difficulty, a potential solution involves fine-tuning embeddings. By fine-tuning the embeddings, the goal is to enhance the accuracy of semantic search and mitigate the issues associated with the assumption that proximity in embedding space guarantees semantic similarity.
Objective
The objective is to demonstrate that fine-tuning embeddings through the retrieval model can narrow the semantic gap and lead to more accurate retrieval, addressing the challenge of retrieval difficulty.
Dataset
The dataset comprises pairs of text, representing questions and potential answers.
Example 1: “How can I analyze large datasets?” paired with “Use Snowflake for efficient large-scale…”
Example 2: “What is the capital of Peru?” paired with “Lima”

Fine-tuning process

A retrieval model, denoted as M, is introduced to fine-tune the embeddings for improved performance. Embeddings are obtained for individual text elements using the get_embedding function, as exemplified by u and v for the questions in the dataset.
Evaluation metrics
The cosine similarity between original embeddings (cosine similarity(u, v)) and the fine-tuned embeddings (cosine similarity(M@u, M@v)) is used as an evaluation metric.
Potential benefits
(i) Fine-tuning embeddings allows the model to learn and adapt to the nuances of the specific dataset, capturing semantic relationships more effectively.
(ii) By incorporating the retrieval model into the process, the system aims to reduce the distance between embeddings for semantically related text chunks, improving the overall retrieval accuracy.
The potential solution of fine-tuning embeddings offers a method to enhance the performance of semantic search in RAG chatbots. This approach seeks to minimize the impact of retrieval challenges by optimizing the embeddings through a dedicated retrieval model, ultimately improving the accuracy of responses to user queries.
Additional ways to improve retrieval
(i) Fine-tune specialized neural search models
Beyond generic embeddings, consider fine-tuning specialized neural search models such as ColBERT, Splade, and SparseEmbed. These models are specifically designed for information retrieval tasks and can be trained on domain-specific data to enhance their performance in capturing semantic relationships between questions and answers.
(ii) Utilize language model manipulation for improved retrieval (HYDE)
Explore methods involving Language Model Manipulation (HYDE), where the language model is employed to create a pseudo-answer for a given question. The generated pseudo-answer is then converted into embeddings, and these embeddings are used for search. This approach leverages the strengths of language models to simulate potential answers, providing an alternative perspective for retrieval.
(iii) Incorporate knowledge graphs
Integrate knowledge graphs into the retrieval process. Knowledge graphs, such as those demonstrated with Neo4J, can represent relationships between entities and provide a structured way to organize information. By leveraging the connections within a knowledge graph, the chatbot can enhance its ability to retrieve contextually relevant answers.
Ensure RAG safety and reliability with Aporia Guardrails
Aporia Guardrails mitigate a wide range of risks and threats that may compromise the safety, reliability, and ethical use of RAG chatbots. These guardrails are crucial components in maintaining a secure and trustworthy conversational environment.
Here’s where Aporia fits in:
1. RAG Hallucinations Mitigation
Aporia Guardrails are equipped to address the challenge of hallucinations in RAG chatbots. This Guardrail implements mechanisms to detect and filter out hallucinatory outputs in real time, ensuring that the RAG chatbot provides reliable and contextually accurate information.
2. Prompt Injection Attack Prevention
Guardrails play a pivotal role in preventing prompt injection attacks. These attacks involve manipulating the input prompts to elicit undesired or unintended responses from the chatbot. Aporia Guardrails incorporates robust validation mechanisms to detect and immediately prevent prompt injection attempts, maintaining the integrity of the chatbot’s responses.
3. PII Data Leakage Safeguards
Guardrails prioritize user privacy by implementing safeguards against Personally Identifiable Information (PII) data leakage. They are designed to detect and prevent the inadvertent disclosure of sensitive user information, ensuring compliance with privacy regulations and maintaining user trust.
4. Profanity Content Filtering
A crucial aspect of Aporia Guardrails is the ability to filter out profanity, better known as Not Safe For Work (NSFW) content. By implementing content filtering mechanisms, the guardrails help ensure that the chatbot’s responses are appropriate and adhere to community and brand guidelines, creating a safer and more inclusive user experience.
5. Off-Topic Detection
A key feature of Aporia Guardrails is the Off-Topic Detection capability, which is designed to recognize and correct responses that deviate from the intended discussion. Through the application of sophisticated monitoring techniques, this feature helps maintain the relevance and precision of AI dialogues, thereby enhancing the overall effectiveness and user satisfaction of AI interactions.
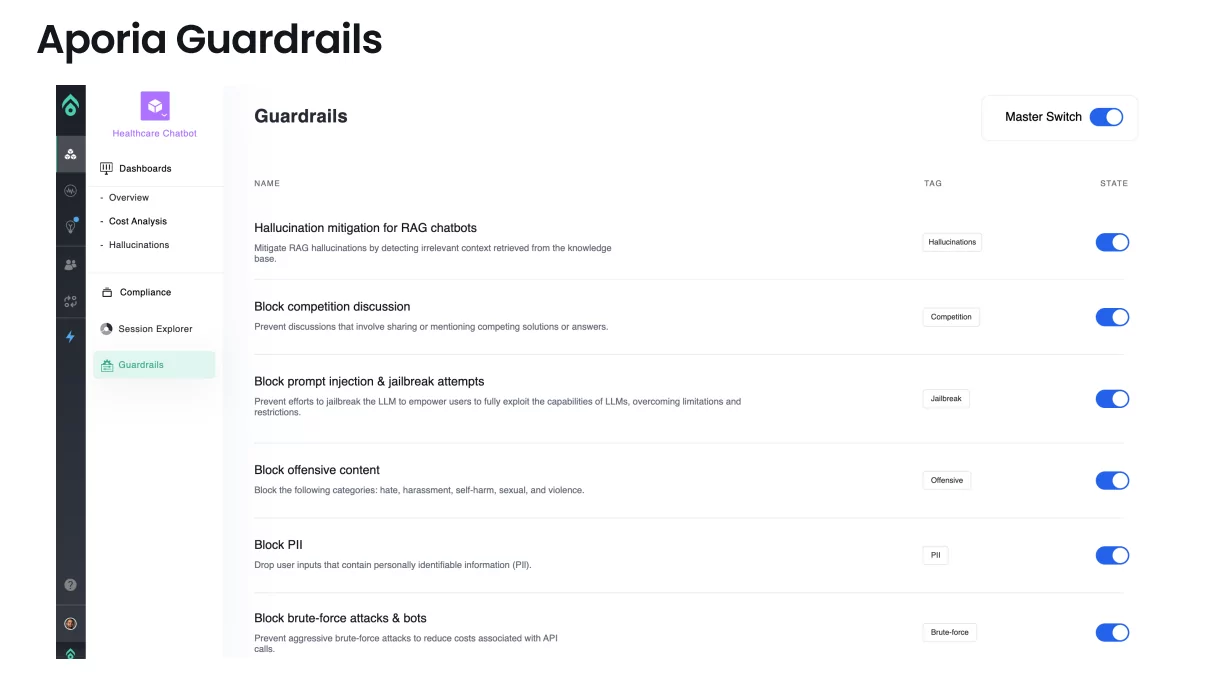
By addressing these challenges through Aporia Guardrails, the overall reliability, safety, and ethical usage of RAG chatbots are significantly enhanced. These guardrails work seamlessly to create a robust defense against potential issues, allowing organizations to deploy chatbots with confidence in their ability to maintain a secure and user-friendly conversational environment. The implementation of Aporia Guardrails reflects a commitment to responsible AI development and deployment, emphasizing the importance of user safety and data privacy in the realm of conversational agents.
Conclusion
The evolution of Retrieval-Augmented Generation (RAG) chatbots brings valuable advancements in leveraging retrieval and generation techniques. While facing challenges like hallucinations and retrieval complexities, solutions like fine-tuning embeddings and specialized neural search models emerge.
A thoughtful, guarded approach is crucial for building trust in AI-powered chatbots. Embracing user-centric practices and these best practices will contribute to responsible AI development. Developers venturing into RAG can utilize these approaches for accurate and secure interactions, fostering a trustworthy conversational environment. Stay tuned for a deeper dive into these strategies and to stay informed on the latest advancements in responsible AI. I hope you found this guide useful, and I welcome any discussions or questions you might have on the topic.
