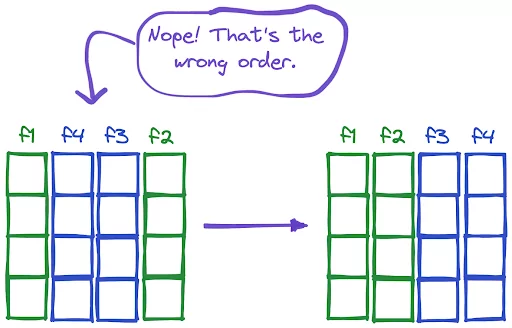
We sometimes want to have particular columns next to each other. In this short how-to article, we will learn how to change the order of columns in Pandas and PySpark DataFrames.
Pandas
We can change the order of columns by reassigning the DataFrame with columns in the desired order.
df = df[["f1","f2","f3","f4"]]
In order to view the entire column list, we can create a list of column names by using the list constructor of Python and the columns method of Pandas.
col_list = list(df.columns)
PySpark
The same approach is valid on PySpark DataFrames. We can use the select method to reassign the DataFrame with columns in the desired order.
df = df.select(["f1","f2","f3","f4"])
The columns method in PySpark returns a list of columns so we do not need to use the list constructor.
col_list = df.columns
This question is also being asked as:
Sorting columns in Pandas DataFrame based on column names.



 Alon Gubkin
Alon Gubkin