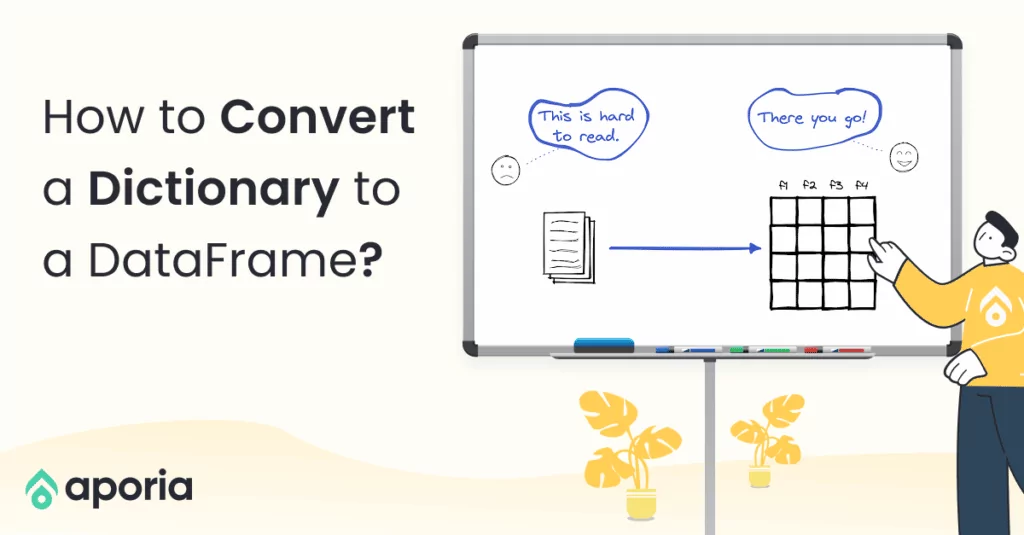
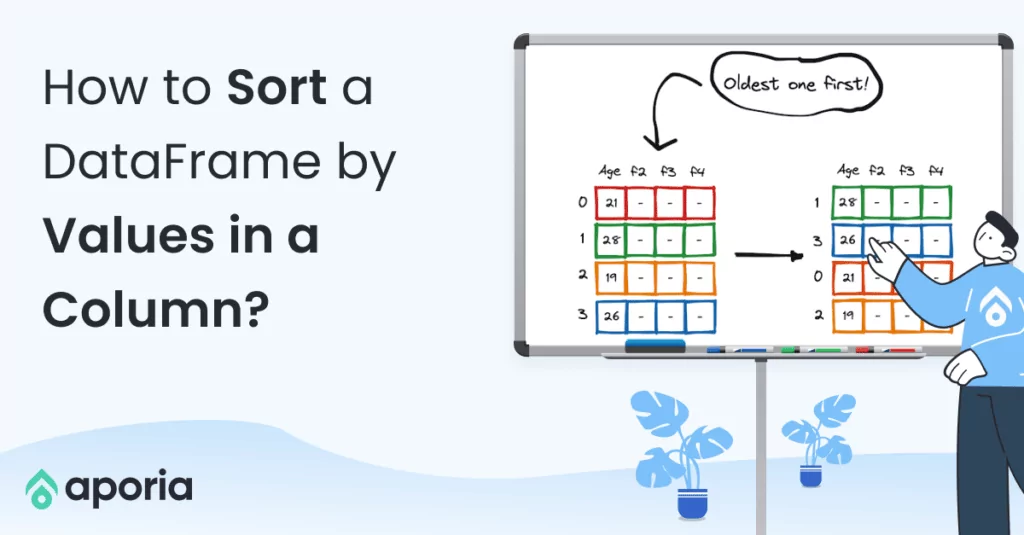
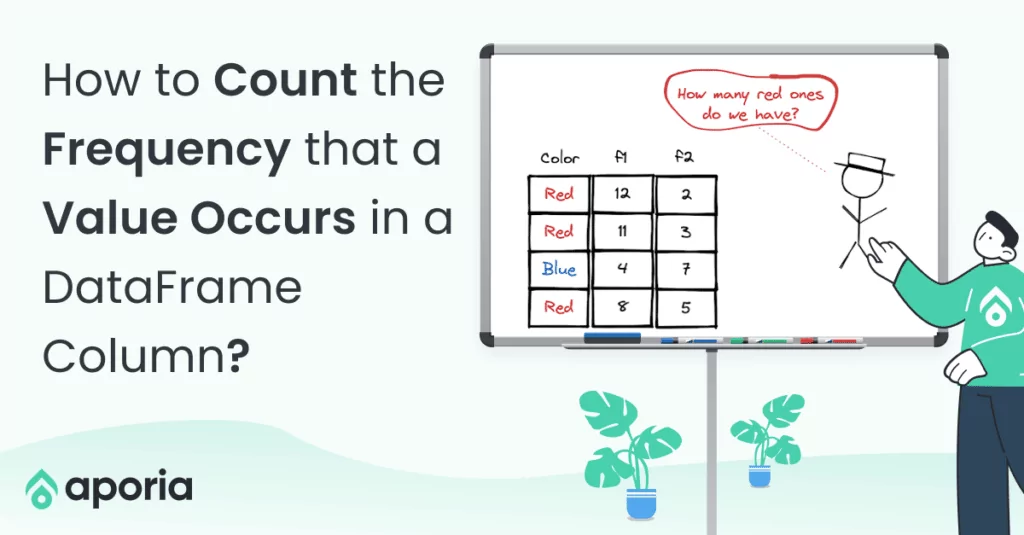
We sometimes need to create columns by combining two or more columns together. In this how-to article, we will learn how to combine two text columns in Pandas and PySpark DataFrames.
Pandas
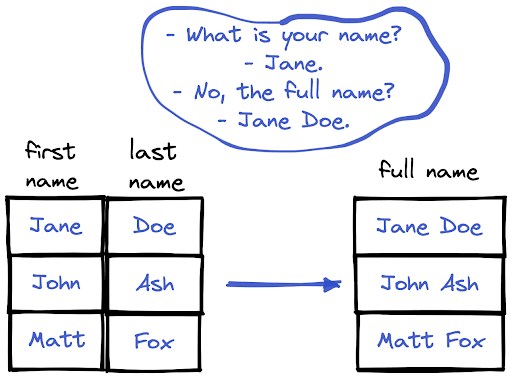
We can combine text columns with the “+” operator.
The expression in between is used for adding a space between the first and last names. Another way of combining text columns is aggregating columns by joining.



 Alon Gubkin
Alon Gubkin