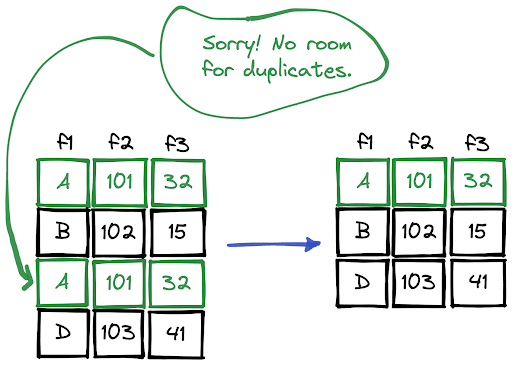
We should not have duplicate rows in a DataFrame because they cause the results of our analysis to be unreliable or simply wrong and waste memory and computation.
In this short how-to article, we will learn how to drop duplicate rows in Pandas and PySpark DataFrames.
Pandas
We can use the drop_duplicates function for this task. By default, it drops rows that are identical, which means the values in all the columns are the same.
df = df.drop_duplicates()
In some cases, having the same values in certain columns is enough for being considered as duplicates. The subset parameter can be used to select columns to look for when detecting duplicates.
df = df.drop_duplicates(subset=["f1","f2"])
By default, the first occurrence of duplicate rows is kept in the DataFrame and the other ones are dropped. We also have the option to keep the last occurrence.
# keep the last occurrencedf = df.drop_duplicates(subset=["f1","f2"], keep="last")
PySpark
The dropDuplicates function can be used for removing duplicate rows.
df = df.dropDuplicates()
It allows checking only some of the columns for determining the duplicate rows.
df = df.dropDuplicates(["f1","f2"])
This question is also being asked as:
How to remove duplicate values using Pandas and keep any one



 Alon Gubkin
Alon Gubkin