In this short how-to article, we will learn how to drop rows in Pandas and PySpark DataFrames that have a missing value in a certain column.
Pandas
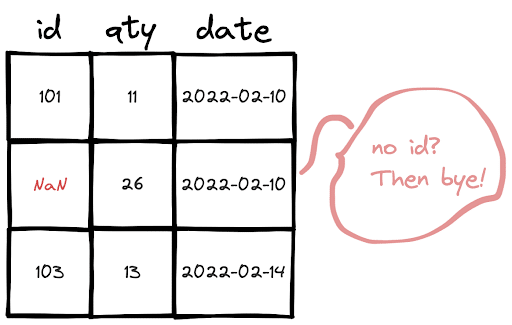
The rows that have missing values can be dropped by using the dropna function. In order to look for only a specific column, we need to use the subset parameter.
df = df.dropna(subset=["id"])
Or, using the inplace parameter:
df.dropna(subset=["id"], inplace=True)
PySpark
It is quite similar to how it is done in Pandas.
df = df.na.drop(subset=["id"])
For both PySpark and Pandas, in the case of checking multiple columns for missing values, you just need to write the additional column names inside the list passed to the subset parameter.



 Alon Gubkin
Alon Gubkin