Shuffling rows in a DataFrame means changing the order of rows. In this short how-to article, we will learn how to do this operation in Pandas DataFrames.
Pandas
We can use the sample method, which returns a randomly selected sample from a DataFrame. If we make the size of the sample the same as the original DataFrame, the resulting sample will be the shuffled version of the original one.
# with n parameterdf = df.sample(n=len(df))# with frac parameterdf = df.sample(frac=1)
The frac and n parameters define the size of the sample.
This question is also being asked as:
Pandas – how do you randomize the rows of a DataFrame


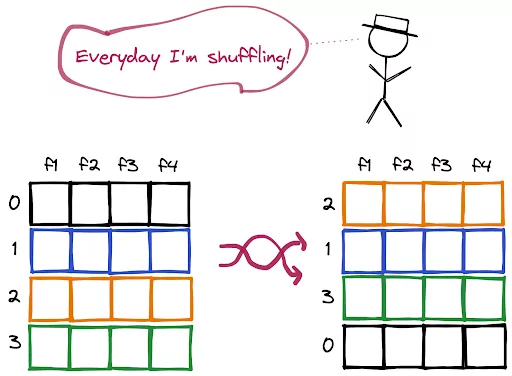

 Alon Gubkin
Alon Gubkin