

April 8, 2024 - last updated
Machine Learning
A practical guide to Normalized Discounted Cumulative Gain (NDCG)
In the world of Machine Learning (ML) and information retrieval, ranking models are integral. Evaluating and improving the performance of these models involves the application of various metrics, one of which is the Normalized Discounted Cumulative Gain (NDCG).
In this guide, you’ll gain a practical understanding of NDCG, its calculation, significance, and applications. We’ll also explore the implications of a low NDCG value, how to handle the absence of relevance scores, ways to use NDCG for model monitoring, and how it fares against other ranking metrics.
Understanding Normalized Discounted Cumulative Gain (NDCG)
NDCG is a commonly used metric in information retrieval, designed to measure the effectiveness of ranking models by assessing the quality of an ordered list of results or predictions. Both the relevance of each result and its position in the list contribute to the NDCG calculation.

Ranking models and recommender systems are typical use cases for NDCG evaluation.
What Is a Ranking Model?
Ranking models are ML models that, given a set of items, predict an ordering based on predefined relevance or importance. They’re employed in search engines, recommendation systems, and personalized advertisement models.
What is a Recommender System?
Recommender systems are technologies that suggest products, services, or information to users based on their past behaviors, preferences, or profiles similar to theirs. They’re prevalent across several sectors, including retail, entertainment, and news platforms, aiming to curate and offer tailored experiences to each user.
Learn more about recommender systems here.
Calculating Discounted Cumulative Gain (DCG)
DCG is the foundation of NDCG. It incorporates the relevance of a query result and its position in the results list. Here’s how we calculate DCG at a specific rank ‘p’:
DCG_p = rel_1 + Σ(rel_i / log2(i + 1)) for i in [2, p]
Ideal Discounted Cumulative Gain (IDCG)
IDCG is the maximum DCG that can be obtained if the results were ideally ranked – arranged in descending order of their relevance. It is used to normalize DCG and calculate NDCG.
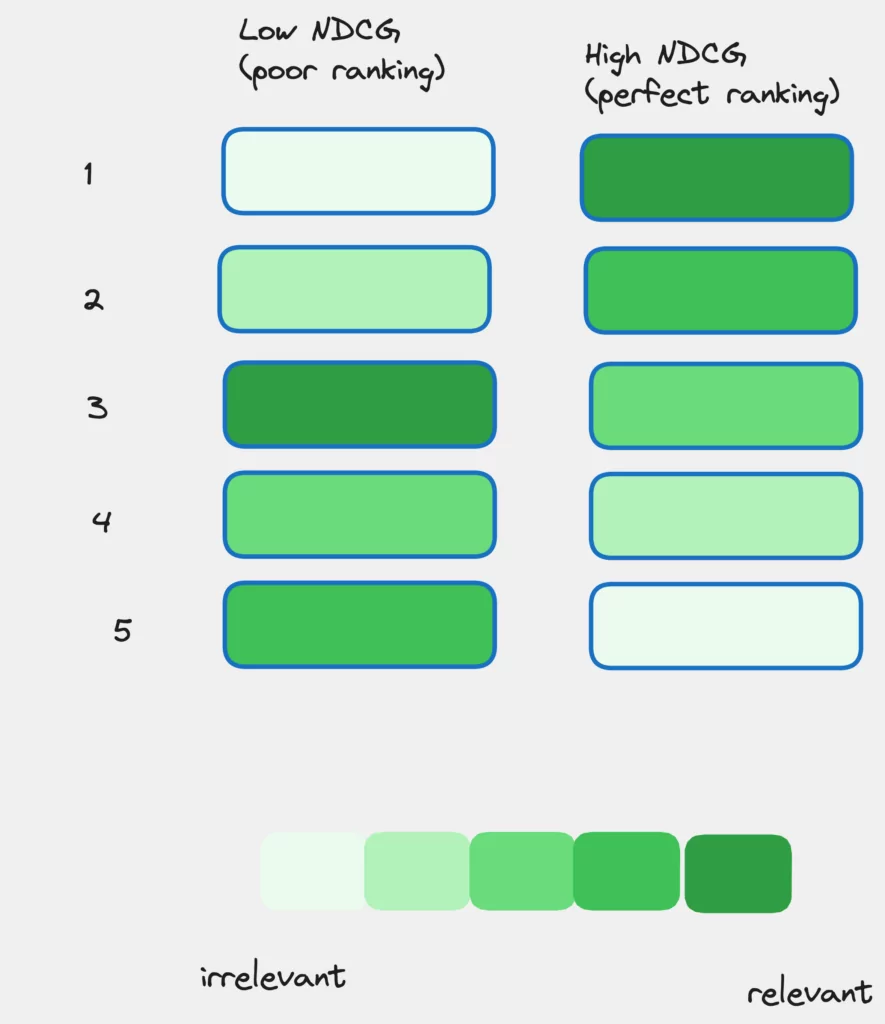
Normalizing DCG to Achieve NDCG
DCG is beneficial, but it can’t be directly compared across different query results due to variations in list lengths and relevance scores. That’s where NDCG comes in with normalization. NDCG is obtained by dividing the DCG score by the IDCG:
NDCG_p = DCG_p / IDCG_p
Interpreting a Low NDCG Value In Production
A low NDCG value signifies a misalignment between the ranking model’s predicted order of results and the actual order of relevance. This could mean that highly relevant results are appearing lower in the list, while less relevant results are higher.
What To Do If Your Model Does Not Have Relevance Scores?
Not all models inherently provide relevance scores. In such instances, you might need to create a method to derive these scores based on your model’s output. You can establish a binary relevance scenario (assigning a score of 1 to relevant items and 0 to irrelevant ones) or employ a set of rules or heuristics specific to your application.
How Is NDCG Used In Model Monitoring?
NDCG is crucial for tracking the performance of ranking models. By monitoring the NDCG value over time, we can spot any decline in model performance. A significant drop in the NDCG score might indicate the need for model retraining or adjustment.
Evaluating Recommender Systems with NDCG
NDCG plays an essential role in assessing the performance of recommender systems. It measures the quality of the ranking by evaluating the relevance of each recommended item and its position in the list. An efficient recommender system should not only predict relevant items but also rank them effectively.
Evaluating Ranking Systems with NDCG
NDCG is also vital in ranking systems, such as those used by search engines. These systems aim to display a set of results in an order relevant to a user’s query. NDCG allows for a quantitative evaluation of the model’s performance by considering the relevance and position of each result in the ordered list.
NDCG in action
Let’s take, for example, a movie recommendation system that suggests a list of movies based on a user’s profile.
The recommendation system returns a list of movie IDs that it thinks the user will like. The actual relevance of each movie is known (perhaps from user ratings or some other ground truth).
The relevance scores might be something like this (where a higher score means the user likes the movie more):
actual = {
'movie1': 3,
'movie2': 2,
'movie3': 3,
'movie4': 2,
'movie5': 1,
'movie6': 2,
'movie7': 3,
'movie8': 3,
'movie9': 1,
'movie10': 3
}The recommendation system might give us a ranking like this:
recommended = ['movie1', 'movie5', 'movie3', 'movie2', 'movie6', 'movie7', 'movie8', 'movie10', 'movie9', 'movie4']Our task is to calculate the NDCG of this ranking. Here’s how we can do it in Python:
import numpy as np
def dcg_at_k(r, k):
r = np.asfarray(r)[:k]
if r.size:
return r[0] + np.sum(r[1:] / np.log2(np.arange(2, r.size + 1)))
return 0.
def ndcg_at_k(r, k):
dcg_max = dcg_at_k(sorted(r, reverse=True), k)
if not dcg_max:
return 0.
return dcg_at_k(r, k) / dcg_max
actual = {
'movie1': 3,
'movie2': 2,
'movie3': 3,
'movie4': 2,
'movie5': 1,
'movie6': 2,
'movie7': 3,
'movie8': 3,
'movie9': 1,
'movie10': 3
}
recommended = ['movie1', 'movie5', 'movie3', 'movie2', 'movie6', 'movie7', 'movie8', 'movie10', 'movie9', 'movie4']
# Convert recommendation list to relevance scores
r = [actual[i] for i in recommended]
print("NDCG@5: ", ndcg_at_k(r, 5))
print("NDCG@10: ", ndcg_at_k(r, 10))In this example, actual is a dictionary that maps movie IDs to their actual relevance scores, and recommended is a list of movie IDs in the order recommended by the system. We first convert this list into a list of relevance scores r and then compute the NDCG for the top 5 and top 10 movies.
Comparison of NDCG vs. other ranking metrics
| Metric | Accounts for Position | Accounts for Relevance | Accommodates Graded Relevance | Holistic Measure |
| NDCG | Yes | Yes | Yes | Yes |
| Precision@k | Partially (up to k) | Yes | No (Binary) | No |
| Recall@k | Partially (up to k) | Yes | No (Binary) | No |
| Mean Avg Precision (MAP) | No (only order) | Yes | Sometimes (depends on implementation) | No |
In the context of ranking metrics, NDCG (Normalized Discounted Cumulative Gain) is more comprehensive as it takes into account both the position and relevance of the results and also accommodates graded relevance.
On the other hand, Precision@k and Recall@k mainly focus on binary relevance and partially account for position up to a specific rank ‘k’. Mean Average Precision (MAP) takes the order into account but not the exact positions, and depending on the implementation, it might or might not accommodate graded relevance. NDCG stands out as a holistic measure among these.
Applications of NDCG
NDCG is integral to optimizing the performance of various ranking systems:
- Search & Ranking Engines: NDCG assists in assessing the ranking quality, making search results more accurate and relevant.
- Recommendation Systems: NDCG allows these systems to measure how well they rank the recommended items.
Personalized Advertisements: NDCG aids in determining how effectively an ad-serving model can rank ads based on user preferences.
Wrapping up NDCG
NDCG is a robust and comprehensive metric in the realm of information retrieval and ranking models. It aids in understanding and optimizing our models, leading to increased user satisfaction and engagement. As we progress towards more advanced ranking systems, metrics like NDCG will continue to shape our interaction with digital systems. Stay connected as we delve deeper into these developments.
