

April 4, 2024 - last updated
Machine Learning
Unlocking the hidden pitfalls of data sampling
While data sampling seems practical, you’re putting your data at risk. Let’s say you’re knee-deep in deploying your regression model. You’ve collected a massive dataset to ensure high-quality predictions, but you’re facing a roadblock – effectively monitoring the sheer volume of predictions. You decide to employ data sampling for monitoring your models’ output. Sounds like a practical solution, right? However, while presenting certain benefits, data sampling brings with it a multitude of risks and challenges.
In this blog, we’ll look at the good, the bad, and the bias of data sampling, and present a more resilient and reliable solution to monitor and track your ML models in production.
Why data sampling sounds ideal
Most legacy and open source ML observability solutions employ data sampling for a reason. It presents a relatively cheaper and more efficient solution in the fast-paced world of machine learning. Let’s look at some key benefits of using sampling in ML observability:
- Computational efficiency: Monitoring big production datasets can be expensive due to the computational demand needed. By using sampling, and looking at a smaller, representative chunk of data, you can still get model insights but use way fewer computing resources.
- Focus: Analyzing the complete dataset may cause engineers to lose focus, getting caught in the noise instead of identifying significant trends or issues. Sampling can highlight core data patterns and common anomalies more clearly, allowing ML teams to focus on mission-critical tasks.
- Decrease in storage requirements: Sampling reduces the amount of data to be stored for monitoring and observability purposes. With computation efficiency in check, this can lead to additional savings in storage space, resources, and associated costs.
While this does paint data sampling as an obvious go-to, there are critical pitfalls when riding the sampling train to reliable ML observability, and we can quickly see how these advantages turn into costly headaches.
The unpredictability of statistical uncertainty
Imagine relying on monitoring a subset of your production data, expecting it to represent the larger set. It’s a considerable gamble, right? Data sampling introduces a significant risk of statistical uncertainty. No matter how rigorous your sampling strategy is, you may not capture the complete diversity of your entire dataset, resulting in missed opportunities and undetected issues with your models’ performance.
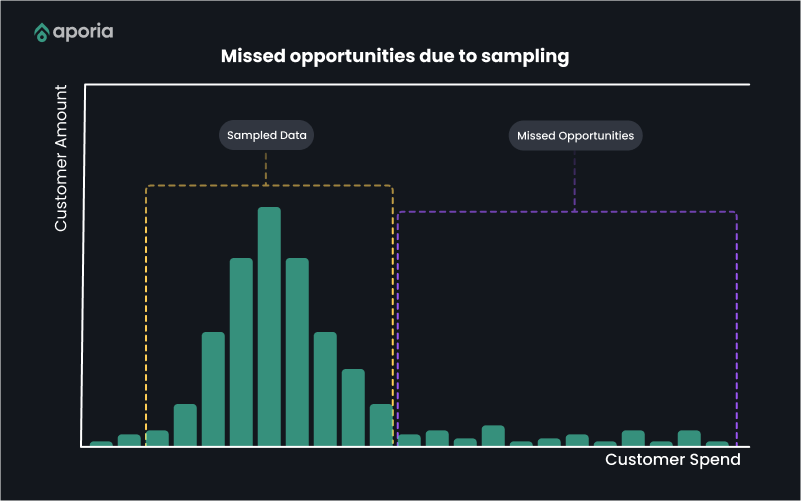
This misrepresentation introduces bias and variance into the observation of your ML models’ behavior. Using skewed data can prevent you from accurately identifying issues with your ML applications in production. This is the inherent problem with sampling – it provides only a subset of the full information, leading to limited observability.
What the uncertainty looks like
Creating a model begins with sampling real-world data, introducing an inherent error rate due to imperfect representation. The goal is to fit the model optimally to this data while avoiding overfitting, which introduces further uncertainty. Then enters model observability, often utilizing data sampling in legacy solutions, adding another layer of uncertainty, and increasing the chances of detecting false errors. Refining the model based on these perceived errors, especially using monitored data for retraining, can inadvertently infuse more uncertainty, underscoring how data sampling in ML observability contributes to both shaping models and the uncertainty in this field.
The underlying problems of ML uncertainty
We’ve established that by sampling, you risk losing crucial information and correlations that exist in the complete dataset. Consequently, you might miss important details, leading to decisions based on incomplete information, and the lingering risks of duplicating production data (which we’ll discuss more in a second). This causes 3 common problems that we frequently see with ML practitioners using legacy ML observability tools:
- Data Drift: Changes in data distribution over time can be hidden when monitoring sampled data, threatening the reliability of machine learning models.
- Performance Metrics & Feature Importance: The use of unrepresentative sampled data can distort performance metrics and feature importance, leading to potentially misguided or unnecessary model retraining adjustments.
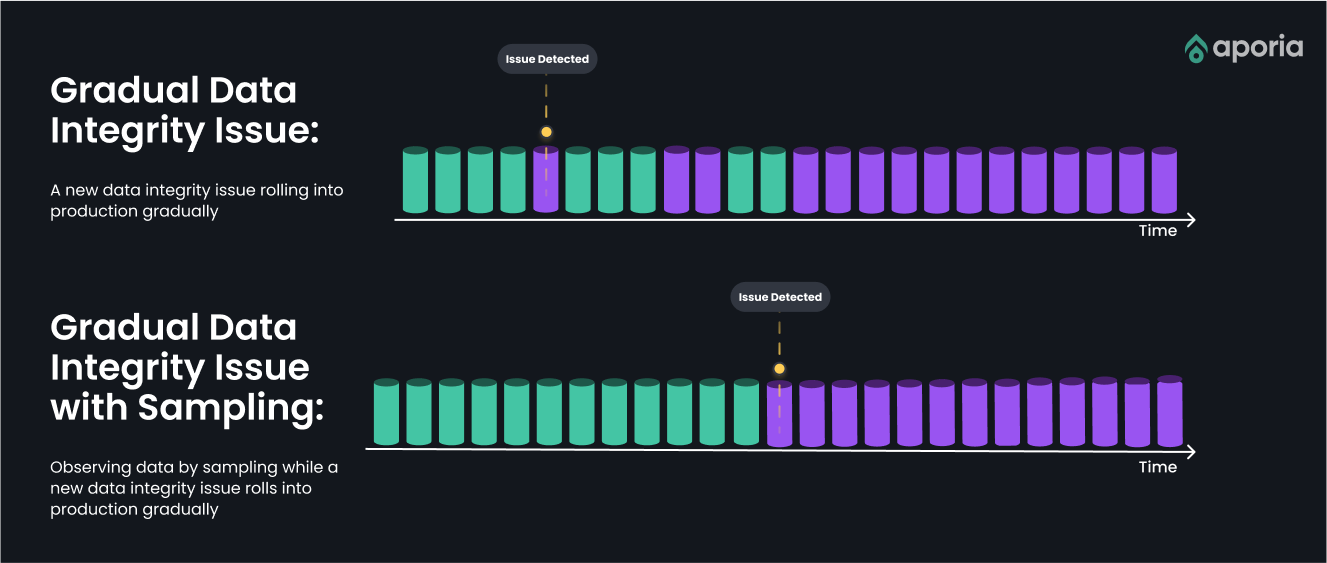
- Delayed Detection of Data Integrity Issues: Data integrity issues can begin subtly within a small data segment. During early sampling, these issues may not be evident, remaining undetected until they grow significantly, affecting a larger user base.
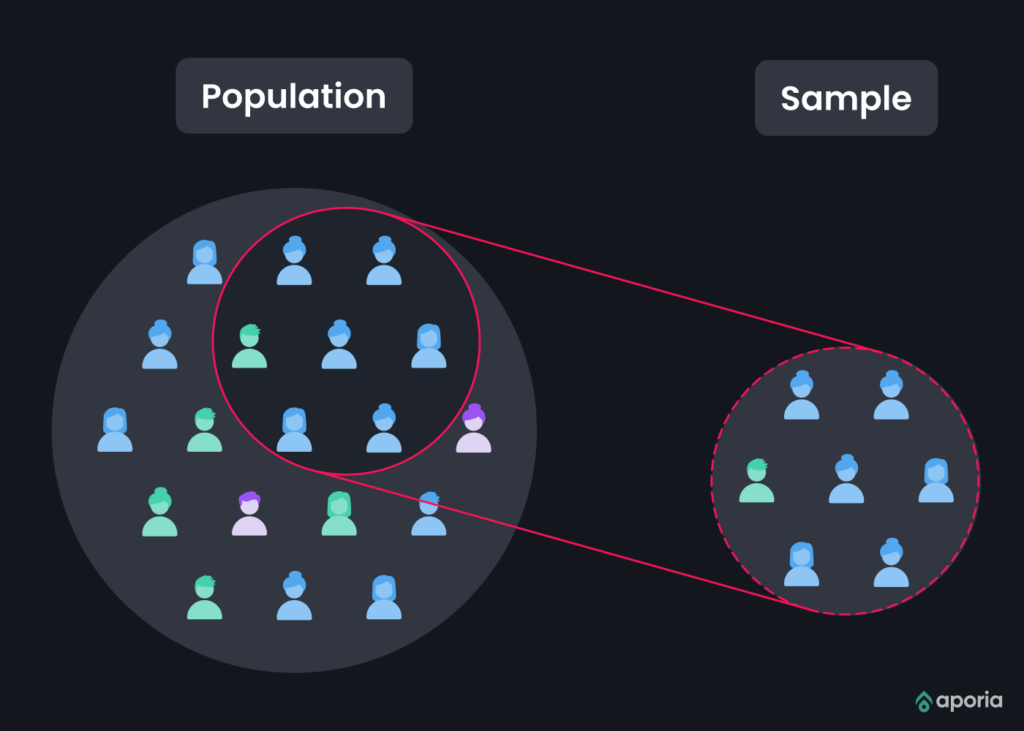
What is Sampling Bias?
Sampling bias occurs when the data collected isn’t representative of the entire population. It can skew results and predictions, leading to inaccurate predictions or models.
Why should you care?
Suppose you’re refining your regression model predicting house prices using a sample dataset skewed towards urban houses. After detecting some inaccuracies related to the number of rooms, you devote resources to improve them. However, due to sampling bias, you may overlook more significant issues like inaccuracies in pricing rural or suburban houses. You’ve spent time fixing a problem that, while present, might not have been the most beneficial area to focus on.
It’s a trap that’s easy to fall into if you’re not careful about ensuring the integrity of the data you’re investigating and that it’s representative of your full dataset. This can lead to inaccurate decision-making and misdirected resources, and ultimately, less effective models.
The risky business of duplicating production data
Another major challenge with data sampling is the need to duplicate your sampled data in order to run it through observability tools. Should be fine, right? After all, it’s an exact mirror of your live system. But here’s the catch – duplicating production data carries substantial data security risks. Any mismanagement or mishandling of your sensitive data by the observability solution can lead to severe privacy and security breaches, tarnishing your reputation and trustworthiness. Not to mention the potential revenue loss alongside the bad PR.
Additionally, when you allow your observability solution to duplicate the data, it essentially locks you into using them exclusively.
Data sampling-free ML observability with Aporia
With these risks in mind, you might wonder, what’s the solution? The obvious cure is to implement a comprehensive, unsampled monitoring system. This involves tracking the entire spectrum of your data, and monitoring model performance across the full dataset, without duplicating the data.
Aporia directly addresses the challenges of data sampling in ML observability with its Direct Data Connectors (DDC). Aporia’s DDC allows monitoring of all your data at once, bypassing the need for sampling, while still ensuring low computational resources.
It directly connects to your data sources, such as Redshift, S3, Athena, Glue, Databricks, Snowflake, etc., facilitating real-time access to your complete datasets. This way, it ensures comprehensive monitoring for billions of predictions and a risk-free method to ensure data integrity, detect drift, and handle any challenges in production.
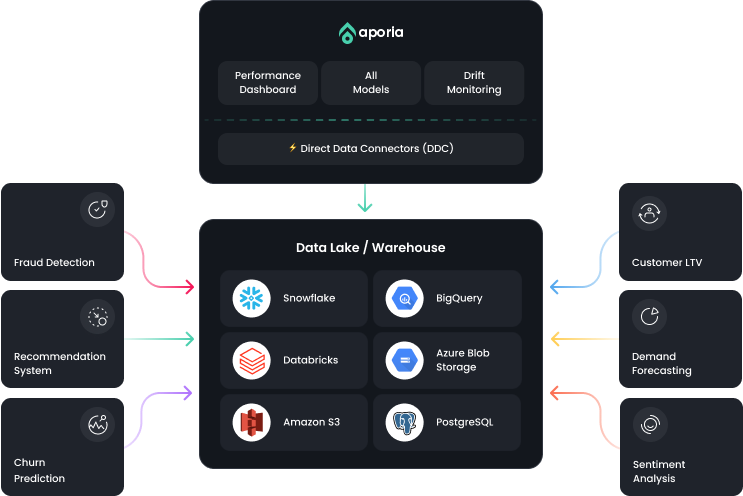
Additionally, DDC eliminates the need for data duplication, by linking directly to your data lake, it maintains a single source of truth to ensure you’re monitoring reliable data.
Legacy model monitoring solutions can incur high cloud costs, especially with large volumes of data. By connecting directly to your data sources and eliminating the need for data duplication, Aporia’s DDC lowers the computational efforts, making it a cost-effective solution for comprehensive ML model monitoring.
Read more about Aporia’s Direct Data Connectors.
The Future: A No-Sampling Zone
It’s crucial to remember that while data sampling and duplicating production data might seem convenient, they carry significant risks and additional costs.
By understanding these potential pitfalls, you can make informed decisions on how to best handle your data, balancing efficiency with accuracy, and ensuring your models are as reliable and effective as possible.
Acknowledging the inherent flaws in data sampling can lead to improving your ML observability, pushing you closer to unlocking the full potential of ML. Want to learn more about ML observability without sampling, try us out or book a demo with one of our experts.
