

April 8, 2024 - last updated
Machine Learning
MLOps is Not Always DevOps
This article was written in collaboration with Anindya Saha (Machine Learning Platform Engineer at Lyft) and Alon Gubkin (CTO at Aporia).
We all dream of building a single, robust model that works everywhere all the time. A “ship-it-and-forget-it”-kind-of model—but unfortunately, for most ML products, this remains only a dream.
We’ve seen entire teams dedicated to continuously improving and shipping better versions of the same ML product. They may deploy multiple ‘competing’ versions of the model to production and conduct A/B tests, or build automated pipelines to retrain and redeploy the model on a periodical basis. This is widely popular in real-time ML products, such as recommendation and personalization systems, price optimization models, and so forth.
Things can get more complex as different model versions can live in different ‘environments’ — development, staging, and production. Traditionally, in DevOps, these environments are isolated to avoid data leakage, a development build ending up in prod, etc. Even though it makes a lot of sense in DevOps, we’ll see how this concept becomes problematic for ML models.
In this blog, we’ll discuss a useful method to manage model versions lifecycle, and then demonstrate why MLOps is not always DevOps.
Model Version Timeline
The model version timeline, which allows us to audit and track the life cycle of different versions of the model, is one of the most useful tools for managing multiple model versions.
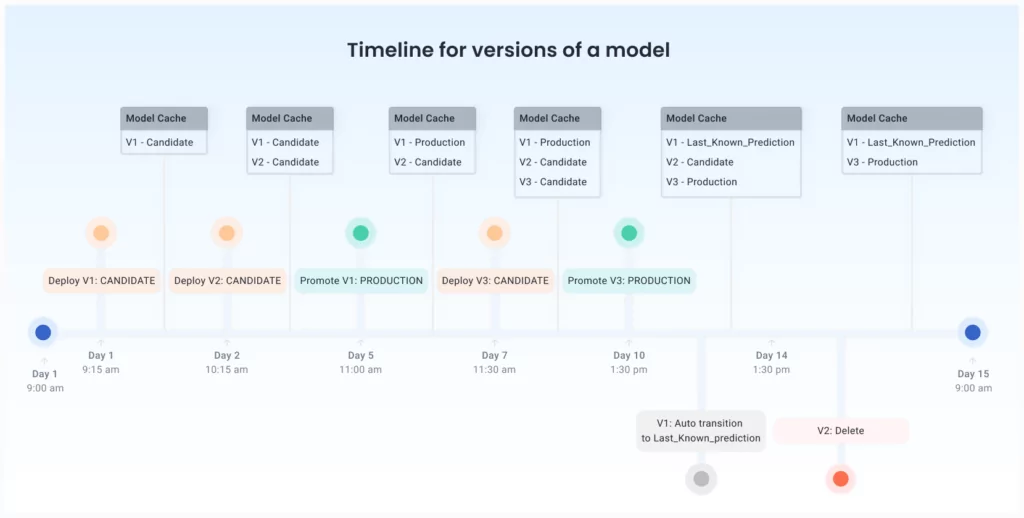
The image above depicts how we can capture a model’s journey on a timeline as it moves through various stages in its life, such as being deployed as a candidate, promoted to production, or deleted.
Tracking model versions over a period of time can give us a sense of how much time is required to productionize models, and until you are able to start employing observability tools, such as drift monitoring and explainable AI.
But this is just the beginning—by attaching performance metrics and business events to the model timeline, we can start answering even more questions.
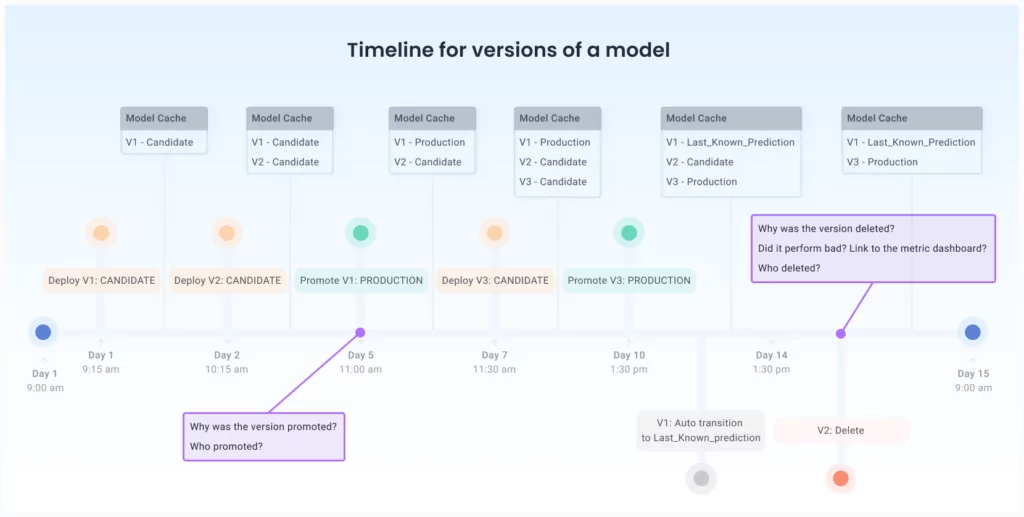
In the image above, we can see that a model version has been deleted. Can we drill down into why this decision was made? Who made that decision? Was it made by a person or an automated pipeline? Can we link to the performance metrics dashboard that shows that the deleted version (V2) performed poorly compared to V1 and V3?
Similarly, when a version is promoted to production, we want to know which business metrics have improved; these metrics should typically be available from the results of an A/B test.
Isolated Environments and MLOps
The tool in the previous section is incredibly useful, but with most ML platform implementations, it’s really hard to implement. Here, we are going to touch on a core pain point of MLOps.
As MLOps evolved from DevOps, it also inherited the pattern of code deployment — CI/CD pipelines to build the software, and then deploy it to development, staging, and finally production. It makes natural sense to do the same for ML models — create a CI/CD pipeline to train the model and deploy it from development, staging, and production.
However, can the same principle really be applied to model artifacts as well?
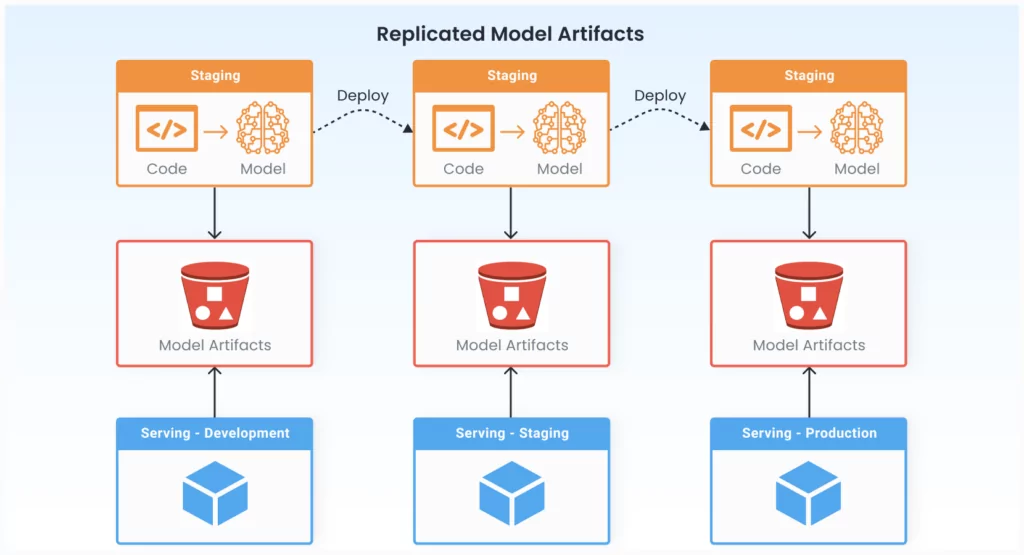
We believe that the answer is no, and here are a few reasons why:
Cross-Environment Model Monitoring and Version Tracking
You might notice that the model version timeline from the previous section includes data from different environments — development, staging, and production. Usually, each environment is completely isolated — different Kubernetes clusters, maybe different VPCs, etc.
Additionally, when monitoring their models, model developers want to see how different development candidates perform versus a production model. With fully isolated environments, building cross-environment tools becomes really hard.
Time-Consuming Nature of Model Training
Training a model requires a considerable amount of time. Usually, in software CI/CD pipelines, the software component gets rebuilt on every deployment, and that’s okay because the build time is usually not that long (or, it’s easy to cache intermediate artifacts).
However — feature engineering, labeling, model training, and finally tuning the model are time-consuming processes and hard to cache. Repeating the same process in different environments unnecessarily complicates the process and increases the time required to train a model threefold.
Single Data Source for Cross-Environment Model Training
Model training across different environments requires access to a single data source. If staging or development environments lack complete production data (or a good representation of the production data), the models trained on sample data may not be representative of the production data — resulting in suboptimal models that perform well in development but poorly in production.
If we train the same model on different sample datasets for the three distinct environments, there is a chance that the best-tuned hyper-parameters will differ. It is preferable to train a single model on a single data source.
One hacky solution is to ask users to train the model once in development on read-only production data, but copy the model artifacts to three buckets: development, staging, and production. The problem is that users frequently forget to upload to all three buckets. Or, they did upload to all three buckets, but made a small change in the development bucket and forgot to make the same change in the staging or production buckets. These steps can be automated via additional ML platform software components, but they result in the duplication of identical model artifacts across three distinct buckets and complications of the process.
Challenges of Promoting Artifacts in Isolated Environments
It’s hard to ‘promote’ artifacts from development to staging to production if each environment is completely isolated. We can try to hack the system such that when the user performs the necessary deployment, promotion, or demotion in production we redo the same operation through a backdoor process in the staging environment too.
But this hack violates environment separation and raises many issues — for example with model identifiers, which should be kept consistent between different environments in order to track them in a model timeline or similar, as shown in the previous section. Auditing the version lifecycle is in itself a complicated process, and adding these additional replication steps makes it even more complicated.
Single Production Environment and Central Repository
To solve these challenges, model developers can work against a single production environment of their ML platform, that can be accessed from different environments of the product.
It is essential to have a central repository of artifacts that can be shared across environments. For development, staging, and production microservices deployments, the serving engine in distinct environments could read from the same repository.
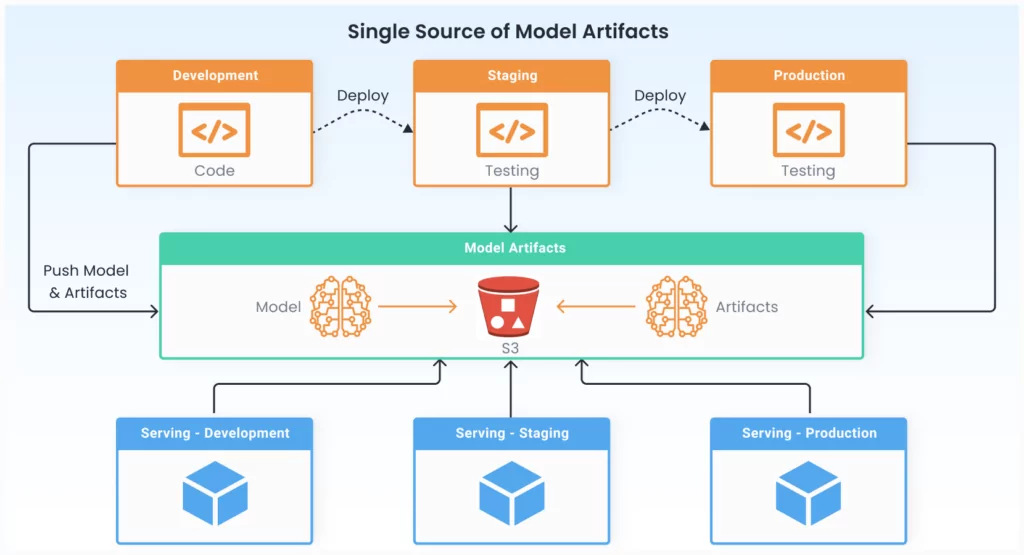
The code used to train the model should flow from development to staging to production, and the same unit test and integration test should be executed at each stage. In addition, models are occasionally retrained on a cadence, but their training code may not change. In such a scenario, each retrain will generate new artifacts, but there will be no code deployment.
Why MLOps is not always DevOps
Although both the MLOps and DevOps fields share some common principles, MLOps has a unique set of challenges that require a specialized approach. We’ve discussed some of the best practices for managing the model version lifecycle, and dealing with isolated environments like production and staging.

It’s important to recognize that these challenges are not meant to be handled in a silo, but by working together and sharing our experiences, we can continue to refine and improve MLOps practices, and drive the industry forward. With a collaborative approach, we can overcome the unique challenges of MLOps and enable more efficient and effective deployment of machine learning models.
