

April 4, 2024 - last updated
Machine Learning
Entity-Level ML Monitoring: Fine-Grained Anomaly Detection
When it comes to monitoring your ML models, the standard approach is to monitor the statistical behavior of entire datasets (e.g. training vs. serving). You can also enhance your monitoring capabilities by monitoring statistical behavior in different segments of your data – different item categories, different states, etc.
In this blog, we’ll discuss monitoring your model at the business entity level and track changes over time to catch important issues that might otherwise go unnoticed. Entities can be specific customers, specific devices, or any (store ✕ item) combinations.
Problem Definition
Entity-level ML monitoring is crucial in various real-world applications, such as:
- Demand Forecasting: Store ID ✕ Item ID
- Customer LTV: Customer ID
- Churn Prediction: Customer ID
- Recommender Systems: Item ID
- Cybersecurity: Device ID
In these applications, dataset-level monitoring could involve, for example, looking at the entire data and comparing the distribution of the prediction over time. Segment-level monitoring involves analyzing specific subgroups or categories within the data. Although these methods can reveal some trends and issues, they may not uncover problems that occur at the individual entity level.
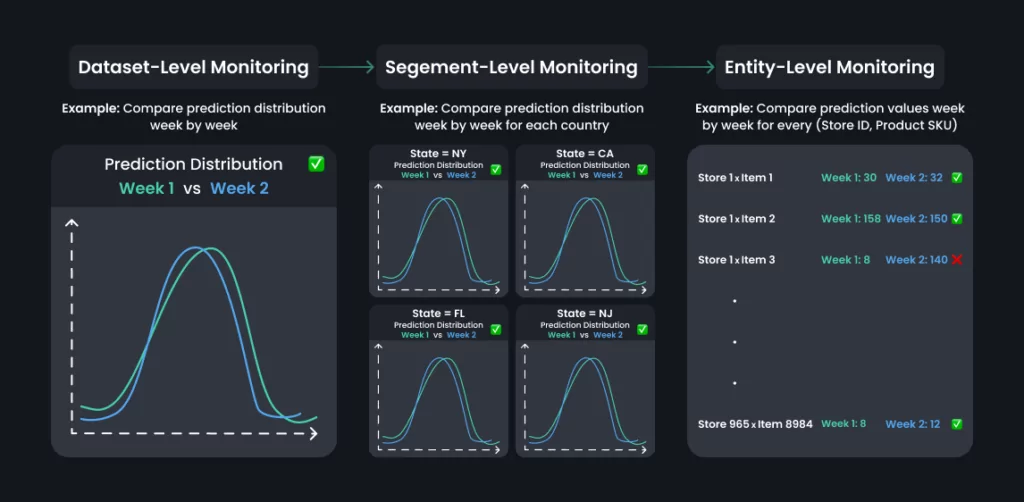
In the example above, when looking at overall distributions between the last week and the week before that, it doesn’t seem like there’s any drift. Moreover, when analyzing specific segments (e.g. different states, different stores, different item categories…), it seems like there is still no drift.
But when looking specifically at store 1 ✕ item 3, we find an issue. While 140 is not an outlier when looking at the overall data or even segment-level data, it is an anomaly for store1 ✕ item3. While the reason for it could be an upcoming sale or marketing campaign, we would expect it to affect more stores and products, maybe even over different segments. However, we can see that we have an increase in the entity-level difference without a matching overall/per-segment drift.
Entity-level monitoring is often challenging. The scale of the data can be very large and there could be millions of different entities to monitor – as opposed to normal data segments (such as U.S. state, country, etc.), where the number of entities is more manageable.
Naive Approach: Using SQL JOINs
A traditional monitoring script to compare the prediction distribution between training and serving might look like this:
# Query model training data and inference data from our database
df_train = spark.sql("SELECT * FROM model_training")
df_serving = spark.sql("SELECT * FROM model_inferences")
# Compute prediction drift
prediction_drift_score = jensen_shannon_distance(
df_train["prediction"],
df_serving["prediction"]
)
if prediction_drift_score >= 0.2:
# ... send alert to Slack ...
To monitor your ML model at the entity level over time, you can join between the current week’s model predictions and the previous week’s model predictions, like so:
SELECT
t1.store_id,
t1.item_id,
t1.prediction_timestamp,
t1.prediction,
ABS(t2.prediction - t1.prediction) / t1.prediction AS weekly_prediction_diff
FROM model_inferences t1
JOIN model_inferences t2
ON
t1.store_id = t2.store_id AND
t1.item_id = t2.item_id AND
t1.prediction_timestamp = t2.prediction_timestamp - INTERVAL '1 week'This query joins the model_inferences table with itself based on store_id, item_id, and the prediction_timestamp from the previous week. Then, it calculates the relative difference between the prediction for each entity from week to week.
You can now detect anomalies in weekly_prediction_diff to see if there’s any drift in a specific store ID/item ID combination week by week.
However, a major problem that surfaces using this approach is when you have large scales of data, as JOIN can become your enemy very quickly. In this case, we just increased our O(n) query to O(n²), potentially reaching trillions of rows.
Better Approach: Using SQL Window Functions
To effectively monitor your ML model at the entity level on large scales of data, you can use SQL window functions to partition the data by the entity and calculate the relative difference over time.
Here’s an example of how to do this using SQL:
SELECT
store_id,
item_id,
prediction_timestamp,
prediction,
-- ... other features ...
ABS(
LAG(prediction) OVER (PARTITION BY store_id, item_id ORDER BY prediction_timestamp) - prediction
) / prediction AS weekly_prediction_diff
FROM
model_inferencesThe JOIN operation can be significantly slower, especially when dealing with large datasets. The LAG() function, on the other hand, is more efficient and can handle large volumes of data more effectively.
Streamlining Entity-Level ML Monitoring Using Aporia
Aporia’s ML observability platform offers a comprehensive solution for monitoring your ML models, including entity-level monitoring. You can detect significant anomalies in your business entities, as well as dive deeper into the data to find the problematic entities.
With Aporia, you can easily integrate your model by querying your inference data using the SQL query above:
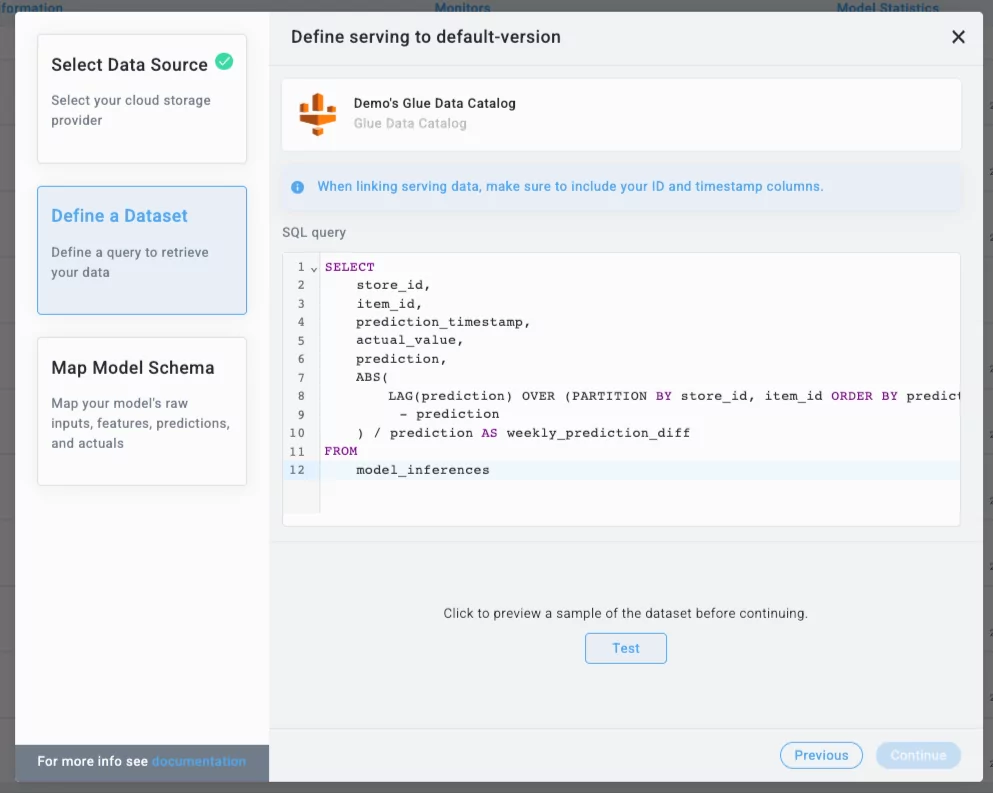
This query contains both model features, predictions, as well as additional metadata. In Aporia, you can map any metadata as a “raw input”.
You can now define custom monitors on weekly_prediction_diff to automatically raise an alert when there’s an anomaly in problematic business entities:
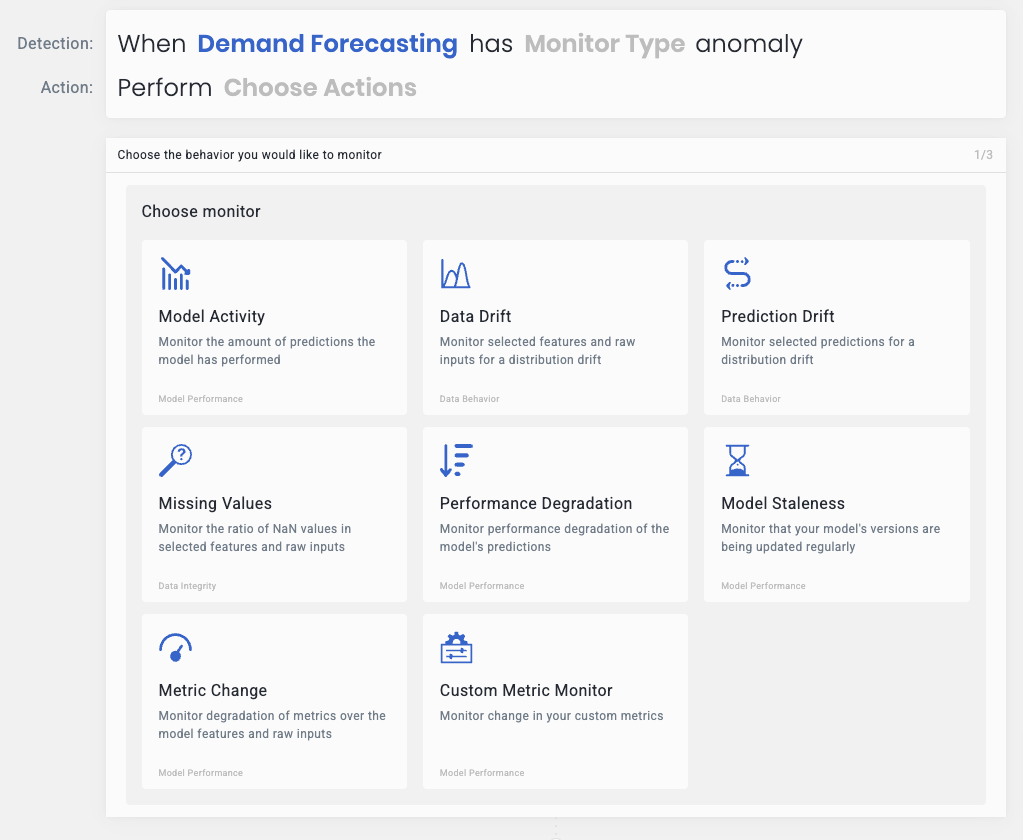
To expand further, we want to avoid false-positive alerts in case of promotions, causing increased sales of multiple items or different stores. We’ll demonstrate the power of Python-based custom metrics in Aporia to accomplish that:
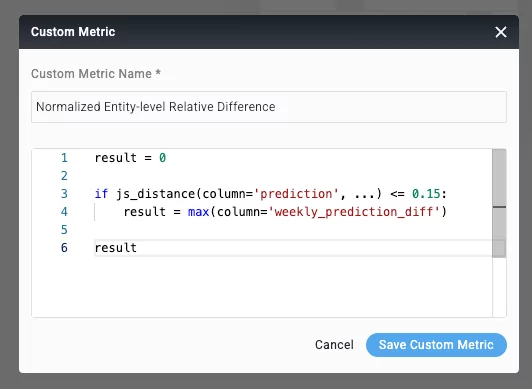
This monitor first checks that there isn’t an impactful drift in our data (which could be caused by an upcoming promotion, holiday, etc), and if so, it returns the relative entity-level difference. This difference is then processed using an anomaly detection algorithm and raises an alert if/when there is an anomaly.
Aporia allows you to send alerts to Slack, Microsoft Teams, Pagerduty, or other platforms. When an alert is raised, Aporia provides investigation tools in order to get to the root cause of the alert (e.g. the problematic entity) as quickly as possible.
If you’re also enthusiastic about entity-level ML monitoring, reach out to us or book a demo.
